In today’s fast-paced business environment, organizations constantly look for ways to stay ahead of the curve. One of the key drivers of this advantage is data and how organizations handle and process it. Historically, batch processing was the norm for data analysis, but as the volume and velocity of data increased, this approach became inadequate. This is where streaming data architecture comes in.
With its focus on processing data as it arrives in motion, streaming data has revolutionized the way organizations handle, analyze, and make decisions based on their data. In this article, we’ll explore the basics of streaming data architecture, its advantages over traditional batch processing, and what the future holds for this powerful approach to data management.
Understanding Data Streams and Stream Processing
Harness the full potential of AI for your business
Data streams, or ‘data in motion,’ are a continuous flow of data generated by various sources, such as IoT devices, clickstream, and log files from cloud-based systems, mobile apps, or social media platforms. In computing, “streaming” refers to the processing of data in a continuous and sequential manner rather than processing it all at once in bulk.
This approach allows for efficient use of resources and can enable real-time processing and analysis of data as it is generated. Processing this fast data in real time requires a new approach to data management, one that is designed to handle high volumes and velocities of data. This approach is known as stream processing.
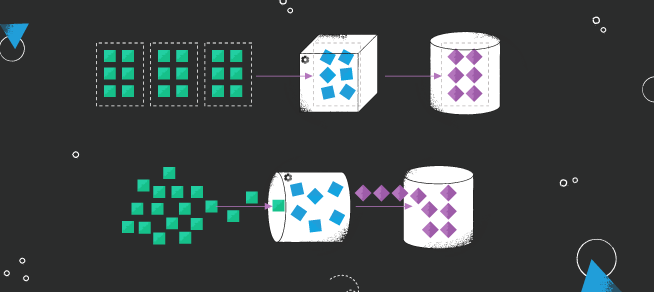
Streaming data processing architecture for continously generated streams of events to be processed and provide data for further applications
Stream processing is designed to process data as it arrives in real-time. This is in contrast to the traditional batch processing approach, which involves collecting and storing data before processing it at a later time. With streaming data architecture, data streams are continuously processed and analyzed, providing organizations with real-time insights into their operations.
Comparing Streaming and Batch Processing
The choice between stream and traditional batch architectures depends on the specific requirements of an organization and the type of data being processed. If we were to provide a short comparison between those two, we could specify the following features:
Batch Processing: Involves collecting and storing data before processing it at a later time. A batch processing system is typically used for more significant amounts of data that can be processed in a batch, such as data from monthly or quarterly reports. It is typically slower and less real-time but can be more cost-effective and less complex than processing data in real-time.
How traditional batch architectures work? Data gathered over a period of time can be later on processed in data sets (batches) to produce analytics
Stream Processing: Involves continuously processing data as it arrives in real-time. Stream processing is designed to handle high volumes and velocities of data and can provide real-time insights and decision-making capabilities. It is typically more complex and resource-intensive than batch but is ideal for handling fast and unpredictable data streams.
Introduction to Streaming Data Architecture Patterns
The two popular patterns in streaming architecture are Lambda and Kappa architectures, each offering unique benefits for processing data in motion.
Continuous stream processing - stream processing tools run operations on streaming data to enable real time analytics
Lambda Architecture
Lambda architecture pattern involves combining batch and real-time processing to handle both historical data and real-time data streams. It involves using a batch layer for processing large amounts of historical data and a speed layer for handling real-time data streams.
Kappa Architecture
Kappa architecture pattern involves only using real-time processing and disregards the batch layer, focusing purely on handling real-time data streams. This architecture pattern is more straightforward and more cost-effective as it eliminates the need for a batch layer. The catch, though, is that it requires a mind switch. From now on, everything is based on a data stream.
But if you decide to implement a modern streaming data architecture and everything becomes stream data in motion, how do you approach batch-like analysis? Enter bounded streams.
Bounded stream processing refers to the processing of data streams with a defined start and end point, where the data is finite and limited in scope. Bounded data streams are contrasted with unbounded data streams, which have no defined end and continue indefinitely.
Bounded and unbounded streams
Streaming data architecture does not only support real-time analytics. With this approach, you can also process bounded streams of data. In bounded stream processing, the data is processed in a specific time window, and all events within that window are processed before moving on to the next time window. This approach is well suited to use cases where the data is of limited scope and size, such as processing data on financial transactions (e.g., transactions from a particular month), customer interactions (e.g., marketing campaign interactions or website traffic statistics), or truck telemetry data (e.g., history of a particular shipment).
Building a Scalable Streaming Data Architecture
Building a scalable streaming data architecture is a challenge but also an excellent opportunity to revolutionize the way businesses handle data. With the exponential growth of data generation, having a scalable architecture is crucial for keeping up with the demands of the data-driven world. The good news is that with the right design, building a scalable streaming data architecture is possible. By leveraging the latest technologies, utilizing modular and flexible designs, and keeping scalability in mind from the start, businesses can ensure that their streaming data infrastructure is ready to tackle even the most massive data challenges.
The first step is to identify the requirements of the use case, including the data sources, data rate, data processing requirements, needs for an operational data lake, and expected outcomes. Once the requirements are understood, it’s important to choose a suitable technology stack that can handle the processing and storage needs of the architecture.
A stream processor will ingest streaming data from input sources, process streaming data, and write the results to output streams. The most popular stream processing tools used to build streaming data architectures are the following:
Alternatively, if you don’t want (or need) to set a stream processor from scratch, cloud providers offer fully-managed services for real-time data processing and streaming data analytics:
Google Cloud Dataflow
Amazon Kinesis Data Streams
Azure Stream Analytics
How to Approach Modern Streaming Architecture
Once the core technology stack for a modern stream processing infrastructure is selected, the whole pipeline needs to be designed with additional software components. Implementing a scalable and fault-tolerant data processing pipeline needs to focus on how to integrate streaming data sources, handle data manipulation, build dedicated data lakes, select analytics tools, and store event data.
It is also essential to consider the specific use cases and applications that will be built on top of the streaming architecture, like machine learning applications. This will inform the design of the data processing pipeline and help ensure that the system meets the needs of the business.
Finally, ongoing monitoring, testing, and optimization are crucial for ensuring the continued success of the streaming architecture. This includes regularly reviewing and tuning the architecture, as well as monitoring key metrics such as data processing times and resource utilization.
The Benefits of Leveraging Streaming Data
By leveraging the power of streaming data, organizations can make data-driven decisions in real-time, leading to improved operational efficiency, reduced latency, and increased customer satisfaction.
Enable Modern Real-Time Data Solutions
Streaming data enables modern real-time data solutions by providing a constant flow of information that can be processed in real-time. Streaming data architectures reflects the need for instant updates in systems like logistics tracking (telemetry data) or ride-sharing solutions that match driver and customer based on multiple integration points and dynamically provide a price for the service. Legacy data processing methods do not provide opportunities for such implementations, hence many enterprise data infrastructures have streaming data architecture at the core.
React to Events as They Happen in Real-Time
By processing data in real time, organizations can respond to events as they happen, providing a competitive edge in terms of speed and agility. This can help organizations make informed decisions, improve operational efficiency, and quickly respond to changing market conditions. Examples of this use case could be instant fraud detection systems, security management systems that constantly monitor security logs, or network analytics that troubleshoot potential connection issues.
Provide Better Customer Experiences
Streaming data can also help organizations provide better customer experiences by allowing them to quickly and efficiently process and analyze customer data in real-time. This can help organizations understand customer behavior and preferences, leading to more personalized and relevant experiences for customers (e.g.,
recommendation engines). Additionally, the ability to process and respond to data in real time can lead to faster resolution of customer needs (e.g. self-service shipment tracking).
Challenges That Come With Streaming Data
The processing of streaming data is associated with several key challenges that must be considered in order to ensure the smooth functioning of the infrastructure. These include:
Flexing with Demand and the Scalability of the Infrastructure
The streaming data processing infrastructure must be flexible enough to handle demand changes, whether due to a sudden increase in data rate or the addition of new data sources. The ability to quickly and easily scale up or down is essential to keep up with the exponential growth in data generation.
Query Processing over Data Streams
A stream-query processor must be able to handle multiple standing queries over a group of input data streams so that it can support a wide range of users and applications. There are two key parameters that determine the effectiveness of processing a collection of queries over incoming data streams: the amount of memory available to the stream processing algorithm and the per-item processing time required by the query processor.
Data Ordering, Data Consistency and Managing Delays
Data from different sources may not arrive in sequential order, and applications must provide mechanisms for sorting incoming events as needed. Continuous streams that may be queried for information can arrive from either a single source or many different ones. Still, ordering and delivering the data is a challenge because they move through a distributed system and will generally have to be processed in the correct order. As data is constantly updated, there is a need to maintain an up-to-date copy of the data, primarily if multiple stream processors are being used. Achieving data consistency may require the use of a quorum or master-slave replication.
Additionally, there may be delays or interruptions to the data stream due to network congestion or other factors.
Fault Tolerance and Reliability
The ability of a system to continue operating correctly in the face of failures of individual components is a necessary property of any distributed system, and streaming data architectures are no exception. The data streaming infrastructure must be robust and reliable, even in the face of individual component failures. Redundancies and replicas may be necessary to achieve this level of fault tolerance.
High Requirements for Storage and Processing Resources (And Therefore $)
Real-time processing of streaming data can be a resource-intensive task, particularly if the data rate is high and/or the sources are distributed. To handle this, powerful processors, GPUs, and fast storage devices may be required for stream processing.
Testing and Debugging Streaming Data Processing
To debug a data stream processing system, it is first necessary to reproduce the system environment and test data. Then, various debugging tools can be used to monitor the system’s performance and identify any bottlenecks or errors.
It is also important to have a method for comparing the process streaming data results with what’s expected in order to verify the correctness of the system. This can be done by using a known dataset and running it through the system or by generating synthetic data that is known to conform to certain properties.
Streaming Data Architecture Use Cases
Stream data processing has several
attractive use cases across various industries, including:
Financial Services: Monitoring stock prices, tracking transactions, and
fraud detection.
Healthcare: Remote patient monitoring, patient data analysis, and EHR updates.
Advertising: Real-time bidding, campaign management, and user behavior analysis.
Energy: Power grid monitoring, renewable energy management, and energy demand forecasting.
These are just a few examples of streaming data analytics. Implementing a streaming platform has the potential to bring real-time insights to many more industries and use cases.
Streaming data is a powerful tool for businesses and organizations to take advantage of in today’s fast-paced digital world. By leveraging the power of real-time data, organizations can react to events as they happen, provide better customer experiences, and unlock a range of new opportunities for innovation and growth.
Building a scalable streaming data architecture requires careful planning and attention to detail, but the benefits are well worth the investment. By approaching modern big data architecture with a focus on stream data and what applications can be built on top of it, organizations can create a foundation that will support their data-driven initiatives for years to come.
At nexocode, our experts have a deep understanding of the challenges and opportunities presented by streaming data architecture. With years of experience building scalable, reliable, and real-time streaming data solutions, we are well-positioned to help organizations of all sizes harness the power of this transformative technology. If you are looking to take your data-driven initiatives to the next level,
don’t hesitate to get in touch with our team of experts. We would be more than happy to help you unlock the full potential of your data.
Wojciech enjoys working with small teams where the quality of the code and the project's direction are essential. In the long run, this allows him to have a broad understanding of the subject, develop personally and look for challenges. He deals with programming in Java and Kotlin. Additionally, Wojciech is interested in Big Data tools, making him a perfect candidate for various Data-Intensive Application implementations.
Would you like to discuss AI opportunities in your business?
Let us know and Dorota will arrange a call with our experts.
Artificial Intelligence solutions are becoming the next competitive edge for many companies within various industries. How do you know if your company should invest time into emerging tech? How to discover and benefit from AI opportunities? How to run AI projects?
Follow our article series to learn how to get on a path towards AI adoption. Join us as we explore the benefits and challenges that come with AI implementation and guide business leaders in creating AI-based companies.
In the interests of your safety and to implement the principle of lawful, reliable and transparent
processing of your personal data when using our services, we developed this document called the
Privacy Policy. This document regulates the processing and protection of Users’ personal data in
connection with their use of the Website and has been prepared by Nexocode.
To ensure the protection of Users' personal data, Nexocode applies appropriate organizational and
technical solutions to prevent privacy breaches. Nexocode implements measures to ensure security at
the level which ensures compliance with applicable Polish and European laws such as:
Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on
the protection of natural persons with regard to the processing of personal data and on the free
movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation)
(published in the Official Journal of the European Union L 119, p 1);
Act of 10 May 2018 on personal data protection (published in the Journal of Laws of 2018, item
1000);
Act of 18 July 2002 on providing services by electronic means;
Telecommunications Law of 16 July 2004.
The Website is secured by the SSL protocol, which provides secure data transmission on the Internet.
1. Definitions
User – a person that uses the Website, i.e. a natural person with full legal capacity, a legal
person, or an organizational unit which is not a legal person to which specific provisions grant
legal capacity.
Nexocode – NEXOCODE sp. z o.o. with its registered office in Kraków, ul. Wadowicka 7, 30-347 Kraków, entered into the Register of Entrepreneurs of the National Court
Register kept by the District Court for Kraków-Śródmieście in Kraków, 11th Commercial Department
of the National Court Register, under the KRS number: 0000686992, NIP: 6762533324.
Website – website run by Nexocode, at the URL: nexocode.com whose content is available to
authorized persons.
Cookies – small files saved by the server on the User's computer, which the server can read when
when the website is accessed from the computer.
SSL protocol – a special standard for transmitting data on the Internet which unlike ordinary
methods of data transmission encrypts data transmission.
System log – the information that the User's computer transmits to the server which may contain
various data (e.g. the user’s IP number), allowing to determine the approximate location where
the connection came from.
IP address – individual number which is usually assigned to every computer connected to the
Internet. The IP number can be permanently associated with the computer (static) or assigned to
a given connection (dynamic).
GDPR – Regulation 2016/679 of the European Parliament and of the Council of 27 April 2016 on the
protection of individuals regarding the processing of personal data and onthe free transmission
of such data, repealing Directive 95/46 / EC (General Data Protection Regulation).
Personal data – information about an identified or identifiable natural person ("data subject").
An identifiable natural person is a person who can be directly or indirectly identified, in
particular on the basis of identifiers such as name, identification number, location data,
online identifiers or one or more specific factors determining the physical, physiological,
genetic, mental, economic, cultural or social identity of a natural person.
Processing – any operations performed on personal data, such as collecting, recording, storing,
developing, modifying, sharing, and deleting, especially when performed in IT systems.
2. Cookies
The Website is secured by the SSL protocol, which provides secure data transmission on the Internet.
The Website, in accordance with art. 173 of the Telecommunications Act of 16 July 2004 of the
Republic of Poland, uses Cookies, i.e. data, in particular text files, stored on the User's end
device. Cookies are used to:
improve user experience and facilitate navigation on the site;
help to identify returning Users who access the website using the device on which Cookies were
saved;
creating statistics which help to understand how the Users use websites, which allows to improve
their structure and content;
adjusting the content of the Website pages to specific User’s preferences and optimizing the
websites website experience to the each User's individual needs.
Cookies usually contain the name of the website from which they originate, their storage time on the
end device and a unique number. On our Website, we use the following types of Cookies:
"Session" – cookie files stored on the User's end device until the Uses logs out, leaves the
website or turns off the web browser;
"Persistent" – cookie files stored on the User's end device for the time specified in the Cookie
file parameters or until they are deleted by the User;
"Performance" – cookies used specifically for gathering data on how visitors use a website to
measure the performance of a website;
"Strictly necessary" – essential for browsing the website and using its features, such as
accessing secure areas of the site;
"Functional" – cookies enabling remembering the settings selected by the User and personalizing
the User interface;
"First-party" – cookies stored by the Website;
"Third-party" – cookies derived from a website other than the Website;
"Facebook cookies" – You should read Facebook cookies policy: www.facebook.com
"Other Google cookies" – Refer to Google cookie policy: google.com
3. How System Logs work on the Website
User's activity on the Website, including the User’s Personal Data, is recorded in System Logs. The
information collected in the Logs is processed primarily for purposes related to the provision of
services, i.e. for the purposes of:
analytics – to improve the quality of services provided by us as part of the Website and adapt
its functionalities to the needs of the Users. The legal basis for processing in this case is
the legitimate interest of Nexocode consisting in analyzing Users' activities and their
preferences;
fraud detection, identification and countering threats to stability and correct operation of the
Website.
4. Cookie mechanism on the Website
Our site uses basic cookies that facilitate the use of its resources. Cookies contain useful
information
and are stored on the User's computer – our server can read them when connecting to this computer
again.
Most web browsers allow cookies to be stored on the User's end device by default. Each User can
change
their Cookie settings in the web browser settings menu:
Google ChromeOpen the menu (click the three-dot icon in the upper right corner), Settings >
Advanced. In
the "Privacy and security" section, click the Content Settings button. In the "Cookies and site
date"
section you can change the following Cookie settings:
Deleting cookies,
Blocking cookies by default,
Default permission for cookies,
Saving Cookies and website data by default and clearing them when the browser is closed,
Specifying exceptions for Cookies for specific websites or domains
Internet Explorer 6.0 and 7.0
From the browser menu (upper right corner): Tools > Internet Options >
Privacy, click the Sites button. Use the slider to set the desired level, confirm the change with
the OK
button.
Mozilla Firefox
browser menu: Tools > Options > Privacy and security. Activate the “Custom” field.
From
there, you can check a relevant field to decide whether or not to accept cookies.
Opera
Open the browser’s settings menu: Go to the Advanced section > Site Settings > Cookies and site
data. From there, adjust the setting: Allow sites to save and read cookie data
Safari
In the Safari drop-down menu, select Preferences and click the Security icon.From there,
select
the desired security level in the "Accept cookies" area.
Disabling Cookies in your browser does not deprive you of access to the resources of the Website.
Web
browsers, by default, allow storing Cookies on the User's end device. Website Users can freely
adjust
cookie settings. The web browser allows you to delete cookies. It is also possible to automatically
block cookies. Detailed information on this subject is provided in the help or documentation of the
specific web browser used by the User. The User can decide not to receive Cookies by changing
browser
settings. However, disabling Cookies necessary for authentication, security or remembering User
preferences may impact user experience, or even make the Website unusable.
5. Additional information
External links may be placed on the Website enabling Users to directly reach other website. Also,
while
using the Website, cookies may also be placed on the User’s device from other entities, in
particular
from third parties such as Google, in order to enable the use the functionalities of the Website
integrated with these third parties. Each of such providers sets out the rules for the use of
cookies in
their privacy policy, so for security reasons we recommend that you read the privacy policy document
before using these pages.
We reserve the right to change this privacy policy at any time by publishing an updated version on
our
Website. After making the change, the privacy policy will be published on the page with a new date.
For
more information on the conditions of providing services, in particular the rules of using the
Website,
contracting, as well as the conditions of accessing content and using the Website, please refer to
the
the Website’s Terms and Conditions.
Nexocode Team
Want to unlock the full potential of Artificial Intelligence technology?
Download our ebook and learn how to drive AI adoption in your business.


 to produce analytics")