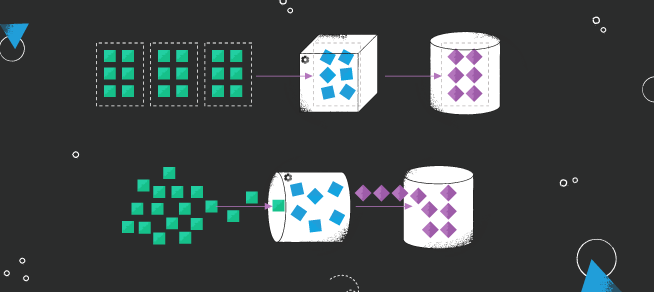
In an era marked by unprecedented rates of data generation, the need for efficient, real-time analytics has never been more crucial. Traditional batch processing systems, designed for handling historical data, often fail to meet the needs of the modern data landscape. This has triggered a shift towards new processing architectures like Lambda and Kappa that can handle real-time data streams more effectively.
While Lambda architecture has been useful, it falls short in some aspects, especially in managing real-time data. Enter Kappa Architecture – a paradigm built to overcome these shortcomings. This architecture uses stream processing at its core, allowing businesses to handle large data streams in real-time.
In this article, we’ll delve into the world of modern streaming architecture, exploring the foundation of Kappa Architecture, its implementation tools, use cases, and the challenges encountered. We’ll also take a peek into the future, revealing why streaming is set to become the new standard for data comprehension in the modern world.
Whether you’re a data professional looking to upgrade your systems or a business leader seeking to leverage real-time data, this article will shed light on how to build a modern streaming data architecture and unleash the power of real-time analytics. Stay tuned.
TL;DR
•Kappa Architecture is a powerful, streamlined approach to modern stream processing infrastructure. It eliminates the need for separate batch and real-time processing pipelines, focusing solely on streaming data architecture.
• The Speed Layer is the bedrock of Kappa Architecture, with tools like Apache Flink, Apache Storm, and Apache Kafka serving as fundamental elements in building a robust streaming data infrastructure.
• Kappa Architecture enables real-time analytics, efficient data lake management, and the seamless processing of both current and historical data. It supports diverse use cases ranging from real-time analytics to month-over-month business analysis.
• Despite its benefits, implementing Kappa Architecture can be challenging, requiring a solid understanding of stream processing and a shift in mindset to view all data in the context of data streams.
• Numerous companies, including LinkedIn, Uber, and Netflix, have successfully implemented Kappa Architecture at scale, reaping benefits in improved data management and analytics.
•The future of data processing is shifting towards streaming architectures. As we generate and process more data in real time, architectures like Kappa will become increasingly relevant and vital.
•Are you looking to implement or optimize a streaming data architecture in your business? Don’t navigate these waters alone. Reach out to the nexocode data engineering experts, who have extensive experience in building scalable data platforms. They’re ready to guide you towards a tailored big data processing solution that suits your specific needs.
Contact nexocode today.
Understanding the Importance of Real-Time Analytics
The shift towards a more interconnected and digital world has brought real-time analytics to the forefront of data strategy. Unlike traditional methods that focus on examining historical data, real-time analytics allows organizations to make decisions and take actions based on what’s happening in the moment. This ability to process and analyze data streams as they arrive presents a powerful tool for businesses to respond swiftly to market changes, detect anomalies, and improve operational efficiency. It paves the way for instant insights that lead to informed decisions, ultimately giving companies a significant competitive edge in today’s fast-paced digital economy. Hence, understanding and harnessing the power of real-time analytics is pivotal to the success of modern businesses.
What is a Data Stream?
A data stream refers to a sequence of digitally encoded, continuously generated data from various sources. Unlike static data sets, data streams are dynamic and flow in real-time, typically produced by a multitude of sources, including sensors, user interfaces, applications, social media platforms, web activities, and financial transactions, among others.
In the context of data processing, a data stream is akin to a conveyor belt carrying a continuous line of information, constantly bringing in new data points for processing and analysis. This characteristic makes data streams particularly useful in real-time analytics and decision-making, where up-to-the-minute data can be crucial.
The Role of Stream Processing in Modern Architecture
Stream processing plays a pivotal role in modern
data architectures, particularly in the face of rising volumes of real-time data. At its core, stream processing involves ingesting, processing, and analyzing data in real-time as it arrives, rather than waiting for full batches of data to accumulate. This enables immediate insights and actions, enhancing the value and utility of data. Read more about stream processing use cases
here.
Historical Data Vs. Streaming Data
Historical data and streaming data are two different but complementary aspects of data processing and analytics. Here’s a brief comparison:
Historical Data
Historical data refers to data collected over time that is stored and then analyzed to identify patterns, trends, and insights to guide future decisions. The key characteristics of historical data include the following:
Static: Once recorded, historical data doesn’t change.
Batch Processing: Historical data is usually processed in large batches, and the analysis is conducted on the complete dataset.
Delayed Insights: As the processing happens after the data has been collected, insights derived from historical data are typically not real-time.
Used for Trends and Forecasts: Historical data is often used for predictive analytics, trend analysis, and statistical modeling.
Streaming Data
Streaming data, on the other hand, refers to data that is generated continuously by various sources. This data is processed in real-time as it arrives. Key characteristics of streaming data include the following:
Dynamic: Streaming data is continuously generated and transmitted.
Stream Processing: Streaming data is processed on the fly, often as soon as it arrives.
Real-time Insights: Since the processing happens in real-time, the insights derived from streaming data are immediate, allowing for prompt actions.
Used for Immediate Actions: Streaming data is often used in scenarios that require immediate action, such as system monitoring, real-time analytics, and instant recommendations.
Stream processing engine components
In modern data architecture, both historical and streaming data have their places. Historical data is valuable for understanding long-term trends and making forecasts while streaming data is crucial for real-time decision-making and immediate responsiveness. A comprehensive data strategy often involves harnessing the strengths of both types of data.
The Past: Batch Processing and Its Limitations
How Batch Processing Handles Historical Data
Batch processing is a method of data processing where similar transactions are grouped together and processed as a batch. In the context of historical data, batch processing involves collecting data over a certain period, storing it, and then processing it all at once.
This method has been the cornerstone of traditional data processing architectures, primarily due to its efficiency in handling large volumes of data. It’s particularly useful when processing power is limited, as jobs can be queued up and processed during off-peak hours, reducing the strain on computational resources.
Batch processing system
Batch processing is handy for analyzing trends over time, producing aggregated reports, and running complex queries that aren’t time-sensitive. For instance, a business may run a batch process overnight to analyze the previous day’s sales data and generate a report for review the next morning.
Shortcomings of a Batch Processing System in the Era of Streaming Data
While batch processing is efficient and effective for certain types of jobs, it has notable shortcomings when handling streaming data and meeting real-time analytics needs.
Delayed Insights: The most significant limitation of batch processing is the delay in insights. Since data is processed in batches, there can be a substantial delay between data generation and data insight, hindering real-time decision-making capabilities.
Inefficiency in Processing Small Batches: Batch processing is most effective when dealing with large volumes of data. However, in the context of streaming data, where information flows continuously, and decisions often need to be made in real-time, processing small batches or individual events becomes crucial. This is something batch processing isn’t designed to handle efficiently.
Resource Intensive: Depending on the volume of data and the complexity of the job, batch processing can be resource-intensive, requiring high computational power and storage capacity.
Handling Real-Time Data: Batch processing is ill-suited to situations where real-time data must be processed immediately upon arrival, such as fraud detection or system monitoring.
As a result, with the rise of streaming data and the increasing demand for real-time analytics, alternative processing methods, such as stream processing and architectures like Kappa, have been developed to overcome these limitations.
How to Approach Modern Streaming Architecture?
As we step into the era of real-time data, the way we handle and process this data plays a significant role in shaping the efficiency of our applications and systems. With the surge in big data and Internet of Things (IoT) applications, we are confronted with the task of dealing with constant streams of data. This has led to the development of new data processing architectures like Lambda and Kappa. Before we delve into the specifics of Kappa, it’s essential to understand its precursor - Lambda architecture.
Lambda Architecture
The Lambda Architecture is a data processing architecture designed to handle massive amounts of data and provide low-latency responses. The architecture divides the data processing into two paths: the batch layer and the speed layer.
The batch layer handles the larger quantities of historical data. It runs extensive computations on the entire dataset to provide accurate views of the data. On the other hand, the speed layer deals with real-time data, offering fast, albeit slightly less accurate insights.
Real-time stream processing and batch processing in Lambda Architecture
This approach allows Lambda architecture to handle both batch processing and real-time analytics effectively, ensuring that organizations get the insights they need in a timely manner.
Lambda architecture based on Kafka for data ingestion with both speed layer implemented with Flink supporing data streaming and batch layer implemented with Spark for batch operations
Limitations of Lambda
While Lambda architecture has been a popular choice for managing big data, it comes with its share of challenges.
Complexity: Maintaining two separate layers for processing (batch and speed) adds a high degree of complexity. It requires writing and maintaining two different sets of codebases, which can be a significant burden for development teams.
Data consistency: Ensuring consistency between the batch and speed layers can be difficult. Inconsistencies can lead to inaccurate data processing and results, which might affect decision-making.
Latency: Although Lambda architecture is designed for real-time data, there can still be delays. The speed layer processes data quickly but with less accuracy, while the batch layer provides more accurate results but takes longer.
This is where the Kappa architecture comes in. By addressing these limitations, Kappa offers a streamlined and efficient approach to processing data streams. But more on that in the next sections.
Introducing the Kappa Architecture
Kappa Architecture represents a shift in the way we approach data processing architectures. Developed as a response to the challenges posed by Lambda architecture, Kappa proposes a simpler, more streamlined approach. The primary aim of Kappa Architecture is to process streaming data in a way that provides timely insights, reduces system complexity, and ensures data consistency. It achieves this by focusing on one core principle: treating all data as a stream.
Speed Layer (Stream Layer) - The Foundation of Kappa Architecture
In Kappa Architecture, the speed layer of the Lambda architecture becomes the foundation, thus also known as the stream layer. Here, all data—whether real-time or historical—is treated as a continuous stream.
Instead of splitting data processing into two separate layers (batch and speed), Kappa focuses on processing data in real-time as it arrives. Historical data in Kappa architecture is just older data in the stream and is handled the same way as new incoming data.
Real-time stream processing in Kappa Architecture
The stream layer ingests the incoming data, processes it, and then passes it downstream for storage or further analysis. This layer’s agility offers lower latency, providing faster, more immediate insights from data streams.
Stream Processing: The Heart of Kappa Architecture
The essence of Kappa Architecture is in its approach to stream processing. Stream processing in Kappa involves continuously querying data as it comes in. This enables real-time analytics, pattern detection, and decision making, all crucial for applications that need instant reactions, like fraud detection or system monitoring.
Continuous stream processing - stream processing tools run operations on streaming data to enable real time analytics
In the Kappa Architecture, the stream processing layer constitutes two key components: the data ingestion part and the data processing part.
Data Ingestion Component: This subsystem shoulders the task of capturing and storing raw data originating from diverse sources like log files, sensor data, and APIs. The influx of data is usually in real-time and is stowed in a distributed data storage system, such as a message queue or a NoSQL database.
Data Processing Component: This subsystem carries the responsibility of manipulating the data as it comes in and preserving the outcomes in a distributed data storage system. It’s typically built using a stream processing engine, like
Apache Flink or Apache Storm, and is engineered to manage large data streams while providing swift and dependable access to query results. In the Kappa architecture, the serving layer doesn’t exist as a separate entity. Instead, the responsibility of delivering query results to users in real time is integrated into the stream processing subsystem.
The components of stream processing in Kappa architecture are built with an eye for fault tolerance and scalability, with each unit carrying out a specific role in the pipeline for real-time data processing.
Moreover, Kappa Architecture’s focus on stream processing significantly simplifies the data processing pipeline. By eliminating the need for a separate batch processing layer, Kappa reduces system complexity, resulting in a more maintainable and scalable architecture.
Popular Stream Processing Tools to Implement Streaming Data Architecture
To effectively implement a Kappa architecture, a robust set of tools is necessary. Among these, stream processing engines play a central role, handling the bulk of data manipulation tasks in real-time. Some of the notable stream processing frameworks include Apache Flink, Apache Storm, and Apache Kafka.
Apache Flink
Apache Flink is an open-source, unified stream-batch processing engine. It offers powerful capabilities for stateful computations over data streams, making it a standout choice for applications that require real-time analytics. With its ability to process large volumes of data with minimal latency, Flink is highly scalable, hence ideal for extensive data processing tasks.
Implementation of streaming data architecture with Apache Flink as stream processor and Apache Kafka as the ingestion layer for input data stream
Apache Storm
Apache Storm is another open-source stream processing engine, designed for processing unbounded streams of data reliably. It’s simple, and it can be used with any programming language, making it a versatile choice for developers. Storm excels in real-time processing and can guarantee that every message will be processed, making it a reliable option for critical data processing tasks.
Apache Kafka
Lastly,
Apache Kafka is a distributed streaming platform known for its high-throughput and fault-tolerant characteristics. Kafka allows for real-time data feed ingestion and can serve as the messaging system between data producers and the stream processing engine. Kafka’s ability to handle real-time data makes it an essential part of any Kappa architecture implementation.
Streaming architecture based on Kafka for Kappa approach - Kafka message flow through components
Beyond Real Time: Benefits of Kappa and Streaming Architecture
As we venture further into the age of big data, the necessity for a modern stream processing infrastructure is undeniable. A suitable data processing architecture should not only address the needs of real-time analytics but also provide a reliable method for managing massive volumes of data. The Kappa architecture, with its focus on streaming data infrastructure, is a comprehensive solution that fits this description.
A comparison between traditional batch architectures and modern stream processing infrastructure that implements kappa pattern
Simplicity and Streamlined Pipeline
One of the key components of Kappa architecture is its simplicity. It treats every input data stream - whether it originates from historical or real-time sources - uniformly, eliminating the need for separate batch and stream processors. This uniformity reduces complexity and coding overhead, making the data pipeline easier to manage, optimize, and scale.
High-Throughput Processing of Historical Data
Although it seems primarily geared towards real-time processing, Kappa architecture handles high-throughput big data processing of historical data with elegance. The architecture enables you to process data directly from the stream processing job, ensuring seamless handling of continuously generated data. You just need to treat all data streams that you want to process in a batch-like-style as bounded data streams.
Bounded and unbounded streams offer different use cases for stream processing.
In Kappa architecture, migrations and reorganizations are simplified due to the single stream processing pipeline. The architecture accommodates new data streams created from the canonical data store, thus enabling seamless data transitions and transformations.
Optimizing Storage with Tiered Approach
Storing data in Kappa architecture can be cost-efficient and performant through the adoption of tiered storage. Although not a core concept of Kappa, tiered storage fits seamlessly into its framework.
Harness the full potential of AI for your business
For example, businesses may store data in a lower-cost fault-tolerant distributed storage tier, like object storage, while allocating real-time data to a more performant tier, like a distributed cache or a NoSQL database. This strategic approach to streaming data storage enables efficient management of data lakes.
Leveraging Kappa for Streaming Data Analytics
Kappa architecture, being a robust streaming platform, integrates well with various data analytics tools. Whether the task is to analyze unstructured data from streaming data sources or to process event data from an event streaming platform, Kappa is capable and versatile.
Challenges of Implementing Kappa Architecture
While the benefits of Kappa Architecture are clear, it’s crucial to also consider its potential challenges. Understanding these challenges can help businesses better prepare for implementation and manage expectations.
Complexity of Setup and Maintenance
Despite Kappa’s inherent simplicity compared to Lambda, setting up and maintaining a Kappa architecture can still pose a degree of complexity, especially for organizations that are new to stream processing frameworks. Understanding the inner workings of the stream processor, managing the input data stream, and dealing with the intricacies of streaming event data can pose challenges that require expertise and experience to overcome.
Cost and Scalability Considerations
One of the more tangible concerns when implementing Kappa architecture is the cost associated with storing big data on an event streaming platform. A potential solution to this challenge is adopting a data lake approach provided by cloud storage services like AWS S3 or Google Cloud Storage. These services can offer scalable and cost-efficient storage solutions that can handle the large volumes of data typically associated with streaming data architectures.
Incorporating a “streaming data lake” into your data streaming architecture is another viable approach. This involves using Apache Kafka as the streaming layer coupled with object storage for long-term data storage. This setup can create a scalable and cost-effective infrastructure, but it requires careful planning and execution to avoid scalability issues and unnecessary costs.
Managing Data Streams for Integrity, Correctness, and Consistency
In any modern stream processing infrastructure, managing continuously generated data is a formidable task. Kappa architecture, with its undivided attention to stream processing, brings its own set of unique challenges, and also opportunities, in managing data streams. Ensuring data integrity, maintaining a smooth flow, and responding to the dynamic nature of data streams requires not only a robust data processing architecture but also a thoughtful approach to system design and management.
Streaming systems are inherently incapable of guaranteeing event order due to the continuous and concurrent nature of incoming data. This trait necessitates certain trade-offs when handling late data.
Streaming data architectures often address this issue by employing strategies such as event-time windows and watermarking. These tactics enable the system to account for out-of-order events efficiently. However, they may introduce inaccuracies, as events arriving post-watermarking could be dropped, creating minor inconsistencies and holes in the data.
To address these challenges, companies like
Uber have innovatively designed their Kappa architecture to facilitate backfilling for streaming workloads using a unified codebase. This solution offers a seamless way to join data sources for streaming analytics and has also shown to enhance developer productivity.
Backfill pipelines recompute data after a certain window of time has elapsed to account for late-arriving and out-of-order events. For example, if a rider delays rating a driver until their next Uber app session, this event might be missed by the streaming pipeline. However, a backfill pipeline with a few days worth of lag can correctly attribute this event to its proper session. In this way, backfill pipelines can counter delays and patch minor inconsistencies caused by the streaming pipeline.
Necessary Mindset Switch: Embracing Continuous Data Streams
One of the fundamental shifts required when implementing Kappa architecture is the change in perspective. Unlike traditional batch architectures, Kappa demands a consistent focus on data as continuous streams. This aspect necessitates a significant paradigm shift that can impact not only the technical aspects but also the strategic and planning facets of data management.
In traditional batch architectures, data is usually thought of in discrete chunks, processed at scheduled intervals. This mindset does not translate well to Kappa, which treats data as a continuous stream that is processed as it arrives. This approach necessitates a different way of thinking about data, one that is more dynamic and instantaneous.
Consequently, implementing a Kappa architecture requires a significant amount of experience with stream processing and distributed systems. As Kappa’s focus is solely on streams, understanding the nuances of handling streaming data sources, such as error handling, data integrity, and real-time processing, is critical.
Streaming Data Architectures with Kappa - Use Cases
Several tech-forward companies have adopted Kappa architecture, leveraging its simplicity and real-time capabilities to handle vast data processing tasks. Here are a few notable examples:
Uber
As mentioned earlier,
Uber is a pioneer in adopting Kappa architecture. The ride-hailing giant uses Kappa architecture for stream processing, specifically for joining data sources for streaming analytics. They also leverage Kappa with
Kafka,
Apache Hive and
Spark Streaming for their backfilling strategy, which enhances the data integrity, correctness, and consistency of their streaming pipelines. This approach allows Uber to cater to various use cases that require differing levels of latency and correctness (data analysis, dynamic pricing, etc.).
Netflix
Netflix, the leading streaming platform, uses Kappa architecture to process and analyze the massive volumes of event data it generates. They’ve built a real-time analytics pipeline using Apache Kafka and Apache Flink for stream processing, allowing them to handle billions of events per day for personalized recommendations and operational analytics. This Kappa architecture implementation supports real-time data ingestion, processing, and analytics at scale, providing valuable insights into user behavior and system performance.
Alibaba
Alibaba, the Chinese eCommerce giant, uses Kappa architecture to process streaming data in real-time. They rely on Apache Kafka and Apache Flink to handle large-scale data processing tasks. Alibaba’s implementation of Kappa architecture allows for real-time analytics and decision-making, particularly useful during high-traffic events like their annual Singles’ Day sale.
Twitter
Twitter uses Kappa architecture for real-time data analytics and data processing. Their event data stream is vast, generated from millions of tweets and engagements happening every second. Twitter’s implementation of Kappa architecture allows for real-time trend detection, spam filtering, and various other streaming data analytics tasks. Twitter’s data processing architecture showcases the robust capabilities of Kappa in handling high-volume, high-velocity data.
Data Processing in the Modern World - Streaming is The Future of How We Understand Data
The advent of technologies like IoT, cloud computing, and AI has triggered a data revolution. In this era of big data, traditional batch processing techniques can’t keep up with the speed, volume, or variety of data. Enter modern streaming data architectures like Kappa, providing a timely solution to these challenges.
The Kappa Architecture, with its elegant, stream-centric approach, promises to reshape how we process and understand data. Its simplicity, scalability, and real-time processing capabilities make it an ideal choice for businesses dealing with continuously generated data from a myriad of sources.
By choosing Kappa, businesses can process vast amounts of data in real-time, uncovering valuable insights that inform decision-making, optimize operations, and deliver superior customer experiences. Indeed, in the ever-evolving landscape of data processing, streaming architectures are no longer an emerging trend but a necessary component of a robust, modern data infrastructure.
As we continue to generate and depend on data at an unprecedented rate, the transition to real-time data processing is not merely a choice, but a necessity. Kappa Architecture, with its focus on stream processing, perfectly embodies this shift towards real-time data processing and analytics.
Implementing a modern streaming data architecture is a significant undertaking, but you don’t have to do it alone. The data engineering experts at nexocode are equipped with the knowledge and experience to help your organization navigate this transition smoothly. Whether you’re just beginning your journey towards a streaming architecture or looking to optimize an existing system,
nexocode’s team can provide the guidance and support you need.
The world of data is in motion - and in this streaming era, the key to success is staying in sync with this flow.
Kappa Architecture is a simplified and streamlined approach to data processing that focuses on real-time stream processing, thereby eliminating the need for separate batch and real-time processing pipelines found in Lambda Architecture. This architecture is particularly suitable for applications requiring real-time analytics and high throughput processing of streaming data.
Kappa Architecture eliminates the batch processing layer found in Lambda Architecture, focusing instead on processing data as a single continuous stream. This makes Kappa Architecture simpler and more efficient, as it reduces the need for duplicative coding efforts. However, it also necessitates a shift in mindset, as data must always be considered in the context of streams.
Stream processing in Kappa Architecture is implemented using powerful tools like Apache Flink, Apache Storm, Apache Kinesis, and Apache Kafka. These tools are key to creating a robust, scalable, and efficient streaming data architecture.
Kappa Architecture brings several benefits, including simplicity, streamlined data processing pipelines, high-throughput processing of historical and real-time data, ease of migration and reorganization, and the potential for tiered storage for cost optimization.
Implementing Kappa Architecture can pose challenges such as the complexity of setup and maintenance, the potential costliness of the infrastructure, and the need for a mindset shift towards thinking of all data as streams. Ensuring data integrity, correctness, and consistency within continuously generated data streams is also crucial.
With over ten years of professional experience in designing and developing software, Dorota is quick to recognize the best ways to serve users and stakeholders by shaping strategies and ensuring their execution by working closely with engineering and design teams.
She acts as a Product Leader, covering the ongoing AI agile development processes and operationalizing AI throughout the business.
Would you like to discuss AI opportunities in your business?
Let us know and Dorota will arrange a call with our experts.
Artificial Intelligence solutions are becoming the next competitive edge for many companies within various industries. How do you know if your company should invest time into emerging tech? How to discover and benefit from AI opportunities? How to run AI projects?
Follow our article series to learn how to get on a path towards AI adoption. Join us as we explore the benefits and challenges that come with AI implementation and guide business leaders in creating AI-based companies.
In the interests of your safety and to implement the principle of lawful, reliable and transparent
processing of your personal data when using our services, we developed this document called the
Privacy Policy. This document regulates the processing and protection of Users’ personal data in
connection with their use of the Website and has been prepared by Nexocode.
To ensure the protection of Users' personal data, Nexocode applies appropriate organizational and
technical solutions to prevent privacy breaches. Nexocode implements measures to ensure security at
the level which ensures compliance with applicable Polish and European laws such as:
Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on
the protection of natural persons with regard to the processing of personal data and on the free
movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation)
(published in the Official Journal of the European Union L 119, p 1);
Act of 10 May 2018 on personal data protection (published in the Journal of Laws of 2018, item
1000);
Act of 18 July 2002 on providing services by electronic means;
Telecommunications Law of 16 July 2004.
The Website is secured by the SSL protocol, which provides secure data transmission on the Internet.
1. Definitions
User – a person that uses the Website, i.e. a natural person with full legal capacity, a legal
person, or an organizational unit which is not a legal person to which specific provisions grant
legal capacity.
Nexocode – NEXOCODE sp. z o.o. with its registered office in Kraków, ul. Wadowicka 7, 30-347 Kraków, entered into the Register of Entrepreneurs of the National Court
Register kept by the District Court for Kraków-Śródmieście in Kraków, 11th Commercial Department
of the National Court Register, under the KRS number: 0000686992, NIP: 6762533324.
Website – website run by Nexocode, at the URL: nexocode.com whose content is available to
authorized persons.
Cookies – small files saved by the server on the User's computer, which the server can read when
when the website is accessed from the computer.
SSL protocol – a special standard for transmitting data on the Internet which unlike ordinary
methods of data transmission encrypts data transmission.
System log – the information that the User's computer transmits to the server which may contain
various data (e.g. the user’s IP number), allowing to determine the approximate location where
the connection came from.
IP address – individual number which is usually assigned to every computer connected to the
Internet. The IP number can be permanently associated with the computer (static) or assigned to
a given connection (dynamic).
GDPR – Regulation 2016/679 of the European Parliament and of the Council of 27 April 2016 on the
protection of individuals regarding the processing of personal data and onthe free transmission
of such data, repealing Directive 95/46 / EC (General Data Protection Regulation).
Personal data – information about an identified or identifiable natural person ("data subject").
An identifiable natural person is a person who can be directly or indirectly identified, in
particular on the basis of identifiers such as name, identification number, location data,
online identifiers or one or more specific factors determining the physical, physiological,
genetic, mental, economic, cultural or social identity of a natural person.
Processing – any operations performed on personal data, such as collecting, recording, storing,
developing, modifying, sharing, and deleting, especially when performed in IT systems.
2. Cookies
The Website is secured by the SSL protocol, which provides secure data transmission on the Internet.
The Website, in accordance with art. 173 of the Telecommunications Act of 16 July 2004 of the
Republic of Poland, uses Cookies, i.e. data, in particular text files, stored on the User's end
device. Cookies are used to:
improve user experience and facilitate navigation on the site;
help to identify returning Users who access the website using the device on which Cookies were
saved;
creating statistics which help to understand how the Users use websites, which allows to improve
their structure and content;
adjusting the content of the Website pages to specific User’s preferences and optimizing the
websites website experience to the each User's individual needs.
Cookies usually contain the name of the website from which they originate, their storage time on the
end device and a unique number. On our Website, we use the following types of Cookies:
"Session" – cookie files stored on the User's end device until the Uses logs out, leaves the
website or turns off the web browser;
"Persistent" – cookie files stored on the User's end device for the time specified in the Cookie
file parameters or until they are deleted by the User;
"Performance" – cookies used specifically for gathering data on how visitors use a website to
measure the performance of a website;
"Strictly necessary" – essential for browsing the website and using its features, such as
accessing secure areas of the site;
"Functional" – cookies enabling remembering the settings selected by the User and personalizing
the User interface;
"First-party" – cookies stored by the Website;
"Third-party" – cookies derived from a website other than the Website;
"Facebook cookies" – You should read Facebook cookies policy: www.facebook.com
"Other Google cookies" – Refer to Google cookie policy: google.com
3. How System Logs work on the Website
User's activity on the Website, including the User’s Personal Data, is recorded in System Logs. The
information collected in the Logs is processed primarily for purposes related to the provision of
services, i.e. for the purposes of:
analytics – to improve the quality of services provided by us as part of the Website and adapt
its functionalities to the needs of the Users. The legal basis for processing in this case is
the legitimate interest of Nexocode consisting in analyzing Users' activities and their
preferences;
fraud detection, identification and countering threats to stability and correct operation of the
Website.
4. Cookie mechanism on the Website
Our site uses basic cookies that facilitate the use of its resources. Cookies contain useful
information
and are stored on the User's computer – our server can read them when connecting to this computer
again.
Most web browsers allow cookies to be stored on the User's end device by default. Each User can
change
their Cookie settings in the web browser settings menu:
Google ChromeOpen the menu (click the three-dot icon in the upper right corner), Settings >
Advanced. In
the "Privacy and security" section, click the Content Settings button. In the "Cookies and site
date"
section you can change the following Cookie settings:
Deleting cookies,
Blocking cookies by default,
Default permission for cookies,
Saving Cookies and website data by default and clearing them when the browser is closed,
Specifying exceptions for Cookies for specific websites or domains
Internet Explorer 6.0 and 7.0
From the browser menu (upper right corner): Tools > Internet Options >
Privacy, click the Sites button. Use the slider to set the desired level, confirm the change with
the OK
button.
Mozilla Firefox
browser menu: Tools > Options > Privacy and security. Activate the “Custom” field.
From
there, you can check a relevant field to decide whether or not to accept cookies.
Opera
Open the browser’s settings menu: Go to the Advanced section > Site Settings > Cookies and site
data. From there, adjust the setting: Allow sites to save and read cookie data
Safari
In the Safari drop-down menu, select Preferences and click the Security icon.From there,
select
the desired security level in the "Accept cookies" area.
Disabling Cookies in your browser does not deprive you of access to the resources of the Website.
Web
browsers, by default, allow storing Cookies on the User's end device. Website Users can freely
adjust
cookie settings. The web browser allows you to delete cookies. It is also possible to automatically
block cookies. Detailed information on this subject is provided in the help or documentation of the
specific web browser used by the User. The User can decide not to receive Cookies by changing
browser
settings. However, disabling Cookies necessary for authentication, security or remembering User
preferences may impact user experience, or even make the Website unusable.
5. Additional information
External links may be placed on the Website enabling Users to directly reach other website. Also,
while
using the Website, cookies may also be placed on the User’s device from other entities, in
particular
from third parties such as Google, in order to enable the use the functionalities of the Website
integrated with these third parties. Each of such providers sets out the rules for the use of
cookies in
their privacy policy, so for security reasons we recommend that you read the privacy policy document
before using these pages.
We reserve the right to change this privacy policy at any time by publishing an updated version on
our
Website. After making the change, the privacy policy will be published on the page with a new date.
For
more information on the conditions of providing services, in particular the rules of using the
Website,
contracting, as well as the conditions of accessing content and using the Website, please refer to
the
the Website’s Terms and Conditions.
Nexocode Team
Want to unlock the full potential of Artificial Intelligence technology?
Download our ebook and learn how to drive AI adoption in your business.