Transfer learning in practice. Image classification for hotel images with fast.ai library
Kornel Dylski
- February 21, 2019 - updated on July 21, 2024
Inside this article:
For some time now, we have been focusing on expanding our skills in AI and Machine Learning, as these are undoubtedly some of the hottest topics in software development. After some delving into deep learning, we decided to create a simple, yet useful application.
Image Classification
Image classification is a well-known task in deep learning, but there is still plenty of space for new projects. Many projects at nexocode are related to travel and leisure industry. That is why we looked for a need in this particular domain which can be addressed with the power of ML algorithms. What we’ve noticed was that booking engine sites are handling massive amounts of hotel images, sometimes of low quality or not of particular interest for travelers, but the main issue here is that the content of the picture is not described. There is no automatic way to classify them or recognize the ones that are not related to the offer. It’s not uncommon that you would need to do the classification manually, but this is where Machine Learning and Artificial Intelligence will turn data into competitive advantage. We decided to classify photos related to the hotel industry, which can have many future uses.
Fast.ai Library
To achieve the goal we have used the
fast.ai library which increases the level of abstraction of PyTorch. It is relatively new, but already supports good practices and is always up to date with advancements in deep learning. It is provided by Jeremy Howard with his (excellent) course, very suitable for creating prototypes of neural networks. It allowed us to focus on decisions rather than coding.
Data Collection and Data Preparation for Image Classification
To perform any machine learning, we need to collect and prepare data, and for image classification, we need a dataset of already classified images. In our case, they were hotel-related images. After research I found some options to collect these.
First, there is always plenty of free to use
datasets. Kaggle is a great source, as well as MIT collections, and many others. For our task, indoor scene recognition dataset fits pretty well. It needed some preprocessing, and there were many more categories than necessary. When it comes to training data, it is always easier when you have more than required, as you can exclude unnecessary ones.
The second option is simply using Google Graphics. They have open API, and GitHub provides a convenient library. First hundred results for each keyword (category) is usually quite accurate. If we need more, you may need to take a brief look at them and exclude the inaccurate images. There is also a third way, to rent a poll, e.g., Amazon Mechanical Turk. In our case, we used the first two options.
I want to mention here, that preparing categories and the whole dataset is quite an important task. In our case, categories should be exclusive. It’s easy to choose two categories which both should contain the same image. What is the difference between a closet and a pantry? We know that a closet can be a pantry. But the network doesn’t know.
Stories on software engineering straight to your inbox
Then we have to split the dataset into two parts: training part, on which we teach the model, and validation part, used to measure its performance. 7 to 3 is an appropriate ratio. Here is a piece of advice, set up a random seed before you start. If you don’t and you try to continue training next time, your split will be different, and validation set can overlap training set. It is a straight way to overfit (and If you don’t have the third dataset to check, you won’t see it). Overfitting is when your network “memorizes” images instead of learning to generalize them.
We should have a roughly similar number of images per category, and we should remember to normalize the images (fast.ai can handle it).
ResNet Neural Network and Transfer Learning
ResNet, is a neural network model from 2015, now with many variants and improvements, but the basic version is still “good enough” for almost every common case. A whole new article would be needed to describe this model properly, but briefly, it is a model which allows adding more layers and going deeper without the loss of results (it resolves the problem of the vanishing gradient).
Now the critical functionality: transfer learning. When we create a neural network from scratch, all weights are initialized with zeros or some random values. And adjusting them for image recognition takes much more time then we have. To save some time we are using a network that is already trained on images with standard categories. Only a few top layers of weights are responsible for choosing the proper class. All layers below are recognize elements with a smaller level of abstraction, i.e. gradients, curves, lines, pixels, etc. So we only have to retrain the top layers from scratch, and slightly adjust the others.
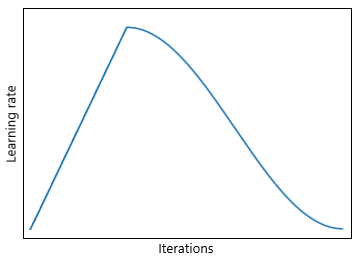
Before training, we have parameter values to choose. The most important is the learning rate (lr). To achieve faster convergence (and maybe better accuracy) learning rate should change during training. The library encourages us to set the learning rate in accordance with the following shape.
We have to choose top value, and the shape will be applied automatically.
Here is how simple run looks like:
# create databunch to load images
np.random.seed(seed)
data = ImageDataBunch.from_folder(path, ds_tfms=get_transforms())
data.normalize(imagenet_stats)
# create learner object with resnet model
learn = create_cnn(data, resnet50)
# learn for 10 epochs
learn.fit_one_cycle(10, lr)
Our model is resnet50, earlier pretrained on imagenet. We are training it for 10 epochs.
But before it, to find proper learning rate (lr) we need to run:
learn.lr_find()
learn.recorder.plot()
Graph shows, how loss changes for different learning rates. We chose value where the loss is still decreasing. Here it is ~ 10-2.
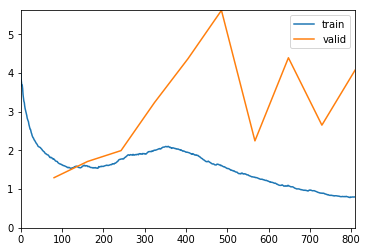
This is how the results look after learning over 10 epochs, with a learning rate of 10-2
This is a plot of losses, for training set and validation set. The network is performing much worse on the validation set. It overfits.
How to Prevent Overfitting?
To prevent overfitting, we have some quick solutions like a dropout, weight decay regularization, and data augmentation.
Dropout is a technique where part of weights is randomly turned off alternately, to enforce the rest of the weights to be more multi-tasking. The network tends to generalize better, and it is reducing overfitting. It is also available in the library, but we won’t use it now.
Weight decay is a regularization technique, where the training algorithm adds penalty when weights values are going too low or too high. Perfect weight values should stick to distribution with mean equaling zero, and standard deviation near to one.
Data augmentation is a technique where images are randomly transformed:, e.g.rotated, zoomed or skewed, so the arrangement of pixels is changing, but the meaning and the labels are the same. It is also available in the library.
And finally, we can always increase the size of the dataset or change the number of epochs.
learn.fit_one_cycle(12, 1e-2, wd=0.1)
Empirical Tunning
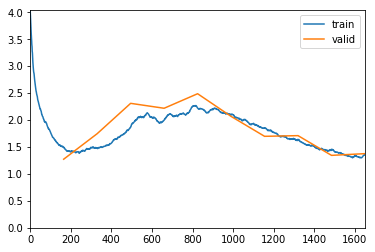
We can see some improvement, but the overall network has a higher loss and lower accuracy, for both sets. Both, weight decay and dropout, if too big, are pushing down network performance. For now, there is no other way to tune them up other than empirical…
learn.fit_one_cycle(15, 1e-2, wd=0.01)
Now, it looks much better. In the end, it’s overfitting a bit, but overall, both sets are improving.
Results are:
metric
value
train loss
0.703716
valid loss
1.000399
accuracy
70,4%
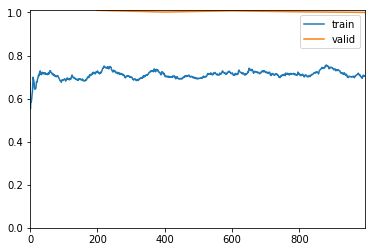
Further training doesn’t improve much.
Conclusions from Transfer Learning
We tried to tune it up in different ways, but still, it’s not getting anywhere near 96% - the level we can get when we train the network to recognize cats vs. dogs. Where is the difference?
Confusion matrix can show us how our network classifies different categories.
The network is classifying most categories correctly (at diagonal), but there are some shortcomings.
99 - front_hotel as outdoor
81 - outdoor as front_hotel
49 - reception as lobby
44 - bar as restaurant
Intuitively some bars can be easily confused with restaurants, as well as a reception with a lobby. Front hotel and outdoor are definitely wrongly chosen categories. After exclusion of unnecessary classes, we can achieve up to 76% accuracy. There is still the missing 20%.
We can look up at the worst classification:
croquettes labeled as 'lobby'
It’s not a lobby, but neither it is a restaurant, as it was marked at the origin. We could correct some wrong labels or remove unrelated images, and we will get another 2–5%.
But actually what network should do with the picture on which the croquettes are? We can’t just add another category labelled as “unknown” because an “unknown dog” is very different from an “unknown jetpack.”
This is a wide field for further research, and I will describe it in the next article.
Kornel is a frontend engineer with several years of experience building robust web applications. Apart from web solutions, he participates in machine learning projects. He has always been interested in physics, which led him to explore artificial intelligence and programming languages such as Python. His focus is on solving technical problems and providing data-driven solutions to clients' needs. He has a creative spirit and loves to make people laugh or smile while working together on complex issues.
What goes on behind the scenes in our engineering team? How do we solve large-scale technical challenges? How do we ensure our applications run smoothly? How do we perform testing and strive for clean code?
Follow our article series to get insight into our developers' current work and learn from their experience. Expect to see technical details, architecture discussions, reviews on libraries and tools we use, best practices on software quality, and maybe even some fail stories.
In the interests of your safety and to implement the principle of lawful, reliable and transparent
processing of your personal data when using our services, we developed this document called the
Privacy Policy. This document regulates the processing and protection of Users’ personal data in
connection with their use of the Website and has been prepared by Nexocode.
To ensure the protection of Users' personal data, Nexocode applies appropriate organizational and
technical solutions to prevent privacy breaches. Nexocode implements measures to ensure security at
the level which ensures compliance with applicable Polish and European laws such as:
Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on
the protection of natural persons with regard to the processing of personal data and on the free
movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation)
(published in the Official Journal of the European Union L 119, p 1);
Act of 10 May 2018 on personal data protection (published in the Journal of Laws of 2018, item
1000);
Act of 18 July 2002 on providing services by electronic means;
Telecommunications Law of 16 July 2004.
The Website is secured by the SSL protocol, which provides secure data transmission on the Internet.
1. Definitions
User – a person that uses the Website, i.e. a natural person with full legal capacity, a legal
person, or an organizational unit which is not a legal person to which specific provisions grant
legal capacity.
Nexocode – NEXOCODE sp. z o.o. with its registered office in Kraków, ul. Wadowicka 7, 30-347 Kraków, entered into the Register of Entrepreneurs of the National Court
Register kept by the District Court for Kraków-Śródmieście in Kraków, 11th Commercial Department
of the National Court Register, under the KRS number: 0000686992, NIP: 6762533324.
Website – website run by Nexocode, at the URL: nexocode.com whose content is available to
authorized persons.
Cookies – small files saved by the server on the User's computer, which the server can read when
when the website is accessed from the computer.
SSL protocol – a special standard for transmitting data on the Internet which unlike ordinary
methods of data transmission encrypts data transmission.
System log – the information that the User's computer transmits to the server which may contain
various data (e.g. the user’s IP number), allowing to determine the approximate location where
the connection came from.
IP address – individual number which is usually assigned to every computer connected to the
Internet. The IP number can be permanently associated with the computer (static) or assigned to
a given connection (dynamic).
GDPR – Regulation 2016/679 of the European Parliament and of the Council of 27 April 2016 on the
protection of individuals regarding the processing of personal data and onthe free transmission
of such data, repealing Directive 95/46 / EC (General Data Protection Regulation).
Personal data – information about an identified or identifiable natural person ("data subject").
An identifiable natural person is a person who can be directly or indirectly identified, in
particular on the basis of identifiers such as name, identification number, location data,
online identifiers or one or more specific factors determining the physical, physiological,
genetic, mental, economic, cultural or social identity of a natural person.
Processing – any operations performed on personal data, such as collecting, recording, storing,
developing, modifying, sharing, and deleting, especially when performed in IT systems.
2. Cookies
The Website is secured by the SSL protocol, which provides secure data transmission on the Internet.
The Website, in accordance with art. 173 of the Telecommunications Act of 16 July 2004 of the
Republic of Poland, uses Cookies, i.e. data, in particular text files, stored on the User's end
device. Cookies are used to:
improve user experience and facilitate navigation on the site;
help to identify returning Users who access the website using the device on which Cookies were
saved;
creating statistics which help to understand how the Users use websites, which allows to improve
their structure and content;
adjusting the content of the Website pages to specific User’s preferences and optimizing the
websites website experience to the each User's individual needs.
Cookies usually contain the name of the website from which they originate, their storage time on the
end device and a unique number. On our Website, we use the following types of Cookies:
"Session" – cookie files stored on the User's end device until the Uses logs out, leaves the
website or turns off the web browser;
"Persistent" – cookie files stored on the User's end device for the time specified in the Cookie
file parameters or until they are deleted by the User;
"Performance" – cookies used specifically for gathering data on how visitors use a website to
measure the performance of a website;
"Strictly necessary" – essential for browsing the website and using its features, such as
accessing secure areas of the site;
"Functional" – cookies enabling remembering the settings selected by the User and personalizing
the User interface;
"First-party" – cookies stored by the Website;
"Third-party" – cookies derived from a website other than the Website;
"Facebook cookies" – You should read Facebook cookies policy: www.facebook.com
"Other Google cookies" – Refer to Google cookie policy: google.com
3. How System Logs work on the Website
User's activity on the Website, including the User’s Personal Data, is recorded in System Logs. The
information collected in the Logs is processed primarily for purposes related to the provision of
services, i.e. for the purposes of:
analytics – to improve the quality of services provided by us as part of the Website and adapt
its functionalities to the needs of the Users. The legal basis for processing in this case is
the legitimate interest of Nexocode consisting in analyzing Users' activities and their
preferences;
fraud detection, identification and countering threats to stability and correct operation of the
Website.
4. Cookie mechanism on the Website
Our site uses basic cookies that facilitate the use of its resources. Cookies contain useful
information
and are stored on the User's computer – our server can read them when connecting to this computer
again.
Most web browsers allow cookies to be stored on the User's end device by default. Each User can
change
their Cookie settings in the web browser settings menu:
Google ChromeOpen the menu (click the three-dot icon in the upper right corner), Settings >
Advanced. In
the "Privacy and security" section, click the Content Settings button. In the "Cookies and site
date"
section you can change the following Cookie settings:
Deleting cookies,
Blocking cookies by default,
Default permission for cookies,
Saving Cookies and website data by default and clearing them when the browser is closed,
Specifying exceptions for Cookies for specific websites or domains
Internet Explorer 6.0 and 7.0
From the browser menu (upper right corner): Tools > Internet Options >
Privacy, click the Sites button. Use the slider to set the desired level, confirm the change with
the OK
button.
Mozilla Firefox
browser menu: Tools > Options > Privacy and security. Activate the “Custom” field.
From
there, you can check a relevant field to decide whether or not to accept cookies.
Opera
Open the browser’s settings menu: Go to the Advanced section > Site Settings > Cookies and site
data. From there, adjust the setting: Allow sites to save and read cookie data
Safari
In the Safari drop-down menu, select Preferences and click the Security icon.From there,
select
the desired security level in the "Accept cookies" area.
Disabling Cookies in your browser does not deprive you of access to the resources of the Website.
Web
browsers, by default, allow storing Cookies on the User's end device. Website Users can freely
adjust
cookie settings. The web browser allows you to delete cookies. It is also possible to automatically
block cookies. Detailed information on this subject is provided in the help or documentation of the
specific web browser used by the User. The User can decide not to receive Cookies by changing
browser
settings. However, disabling Cookies necessary for authentication, security or remembering User
preferences may impact user experience, or even make the Website unusable.
5. Additional information
External links may be placed on the Website enabling Users to directly reach other website. Also,
while
using the Website, cookies may also be placed on the User’s device from other entities, in
particular
from third parties such as Google, in order to enable the use the functionalities of the Website
integrated with these third parties. Each of such providers sets out the rules for the use of
cookies in
their privacy policy, so for security reasons we recommend that you read the privacy policy document
before using these pages.
We reserve the right to change this privacy policy at any time by publishing an updated version on
our
Website. After making the change, the privacy policy will be published on the page with a new date.
For
more information on the conditions of providing services, in particular the rules of using the
Website,
contracting, as well as the conditions of accessing content and using the Website, please refer to
the
the Website’s Terms and Conditions.
Nexocode Team
Want to be a part of our engineering team?
Join our teal organization and work on challenging projects.