Process & Story
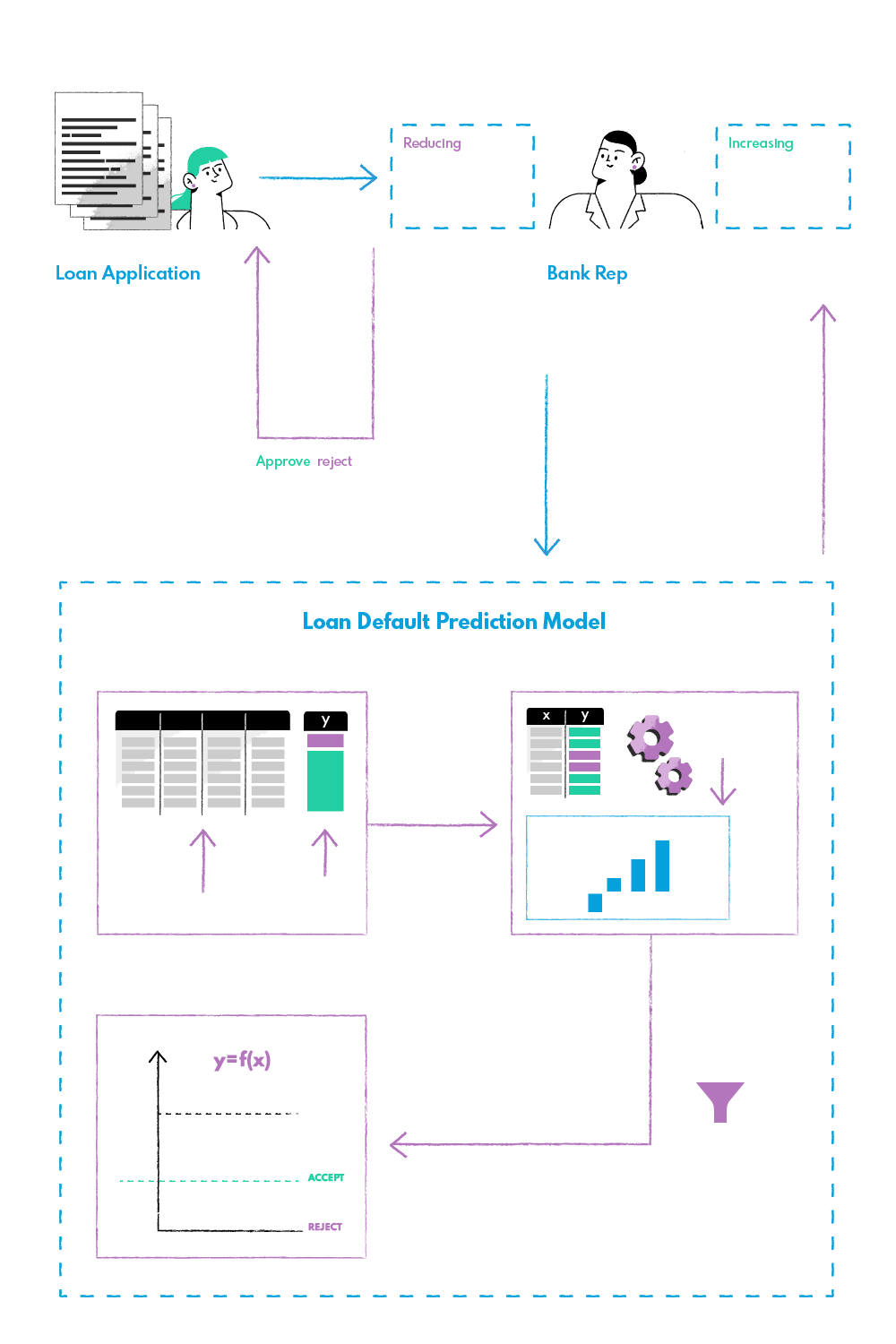
A company from the fintech industry was trying to develop an AI model that could predict bank loan defaults in order to use the information for profit maximization. The company has access to a large dataset of customers’ credit records and other related data on their customers’ activity that could potentially be used to automate credit scoring and streamline the decision-making process for credit approval.
Problem
In the current credit scoring systems, it is a very time-consuming process for agents to manually look through all of the documents and other information to decide on the loan approval. In addition, there was no comprehensive way to determine which customers would default on their loans without manually going through every case file. On the other hand, banks gain additional interest rates from clients late with their installments, so the credit decision should also be optimized for bank profit maximization.
Solution
To predict loan defaults, we applied logistic regression, which is a parametric machine learning algorithm that models the probability of falling into either one of the binary classes (client will default with his loan or have a clear payment status).
The model was trained with historical data on loan defaulted clients to learn the patterns which are related to defaults.
The results of the logistic regression showed that besides some apparent features like credit score, debt to income ratio, or duration of the credit history, there were also some other less obvious ones that proved to be significant for predicting the bank loan default (e.g., demographic data, homeownership).
Due to the fact that the existing dataset is not balanced, which means that there are many more customers with clear loan status than customers who default, we used the sampling method to address this issue. The sampling method is a special case of statistical inference where observations are selected from a population to answer a question about the whole population.
Another important part of the solution was to make it interpretable and easy to understand for business users, so they can easily identify which features have the highest impact on predicting defaults. If the model is too complex and difficult to comprehend, it will be hard for bank agents to use it as a useful tool for decision-making.