Process & Story
Our client builds intelligent machines that automate the collection of recyclable bottles and cans, known as Reverse Vending Machines. To ensure the accuracy of returns and prevent fraud, they needed a solution that could verify an object’s shape, material, and barcode, including distinguishing eligible packages from lookalikes and damaged containers.
We designed a lightweight machine learning system tailored to their hardware and performance constraints. The result? A scalable, fast packaging recognition system ready for nationwide deployment.
Problem
The client’s machines operate in the context of a deposit return scheme. That means they don’t just need to accept recyclables, they must:
- Match the scanned barcode to the actual package,
- Verify the physical condition of each item (no crushed or misshapen bottles),
- Detect fraudulent attempts, like scanning a valid EAN code and inserting a non-eligible copycat.
All of this needs to happen in real time on a compact Raspberry Pi 5, inside a public-facing machine.
Solution
We designed and delivered a real-time object recognition system that helps our client verify recyclables and prevent fraud in deposit return machines. The solution combined custom dataset development, lightweight model training, and edge deployment—all optimized to run on Raspberry Pi 5 within a strict 500ms time budget.
Outcomes
- Custom dataset built from high-resolution machine-captured images, tailored to the real-world packaging types and fraud scenarios
- Accurate object recognition achieved through lightweight segmentation and classification models optimized for edge deployment
- Sub-500ms inference time on Raspberry Pi 5, enabling real-time fraud detection and package validation
- End-to-end ML pipeline delivered, including data ingestion, deduplication, labeling workflow, model training, optimization, and packaging
- Experiment tracking and performance benchmarking via Neptune.ai and ONNX Runtime, ensuring transparency and reproducibility
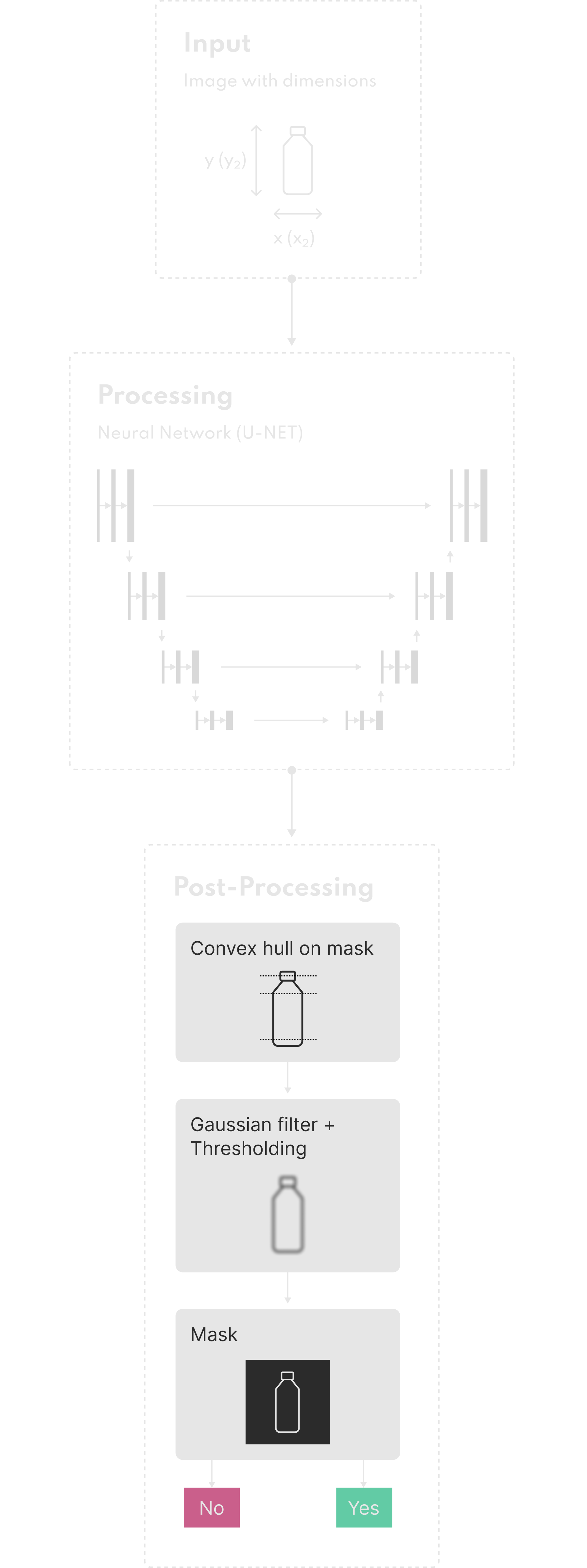
Custom dataset and labeling pipeline
To build a model capable of verifying both object type and condition, we developed a tailored dataset from high-resolution images captured directly by the client’s machines. Since existing public datasets lacked the precision or licensing required, we established a custom ingestion pipeline to organize raw image archives, eliminate duplicates, and preserve metadata such as object dimensions and material.
We deployed a self-hosted instance of Label Studio and onboarded an external labeling team to efficiently annotate thousands of samples. Clear labeling guidelines and active feedback loops ensured accurate segmentation, even in edge cases like open bottle caps or pull-tabs. This labeling infrastructure was designed for reusability—allowing the client to expand the dataset and improve accuracy over time.
Iterative model development for segmentation and verification
We evaluated existing image segmentation models but found them too large or slow for on-device execution. Instead, our team took an iterative approach: a data scientist built an initial segmentation model optimized for quality, which was then fine-tuned, ported, and tested by an ML engineer for performance on the target hardware.
Each iteration was tracked using Neptune.ai, with benchmark metrics including per-image inference time and hardware compatibility via ONNX Runtime. This approach allowed us to gradually reduce model complexity while preserving accuracy, ultimately delivering a version that met both speed and reliability thresholds.
Lightweight, deployable architecture
To simplify installation and updates, we shipped the entire solution as a versioned Python package (.tar.gz), including:
- The final trained model,
- Inference scripts optimized for the client’s setup,
- A requirements list to streamline dependency management.
This modular packaging strategy reduced update sizes and made it easy for the client to deploy the solution at scale across multiple machines, even in bandwidth-limited environments.
Ready for future expansion
The system architecture supports future needs like:
- Adding classification for brands or deposit eligibility,
- Including new object types (e.g. glass containers),
- Fine-tuning models as more labeled data becomes available,
- Integrating with fraud detection dashboards and analytics tools.
The final solution delivers accurate, real-time image analysis at the edge, enabling secure, fraud-resistant recycling flows, with no cloud connectivity required.