CI and CD are concepts that have been around for a long time, but the specifics of implementing them often can be murky. Continuous integration and delivery are critical components of modern software development, and GitLab has some fantastic features for creating pipelines. Gitlab documentation is excellent, but when I learn, I need an understanding of fundamental principles - it allows me to build knowledge upon it. This article will cover what GitLab CI/CD pipelines do and look at some of the best practices you should keep in mind when setting up your own continuous integration or delivery pipeline.
The project is agnostic when it comes to the language or technology used in the project so that anyone can read it.
It is impossible to create a CI/CD pipeline on our local machine.
Continuous integration won’t work because everything would have to be integrated by you, whenever you decide to pull changes from the remote repository and trigger validating commands, e.g., running unit tests.
Stories on software engineering straight to your inbox
Continuous deployment also won’t work because you will have to trigger all deployment tasks manually, which is very risky. After all, the environment where you run commands may change during the time, and build results may differ.
It would be best if you simply had some environment that is predictable and where all jobs can be done. Yes, it is GitLab.
Gitlab is a DevOps platform. It is not just a git repository but also a set of tools that allows you to run unit tests, execute a build job, deploy an application, and many, many more. In short words, it will enable you to configure CI/CD pipelines.
Since it is a web application, it may be accessed by any team member, which allows fruitful collaboration, which is necessary for the software development lifecycle.
To define CI/CD pipeline, you need to create in your repository a .gitlab-ci.yml file located in the root directory of the project that illustrates pipeline configuration, including jobs and pipeline stages. It is a yml file, which GitLab interprets.
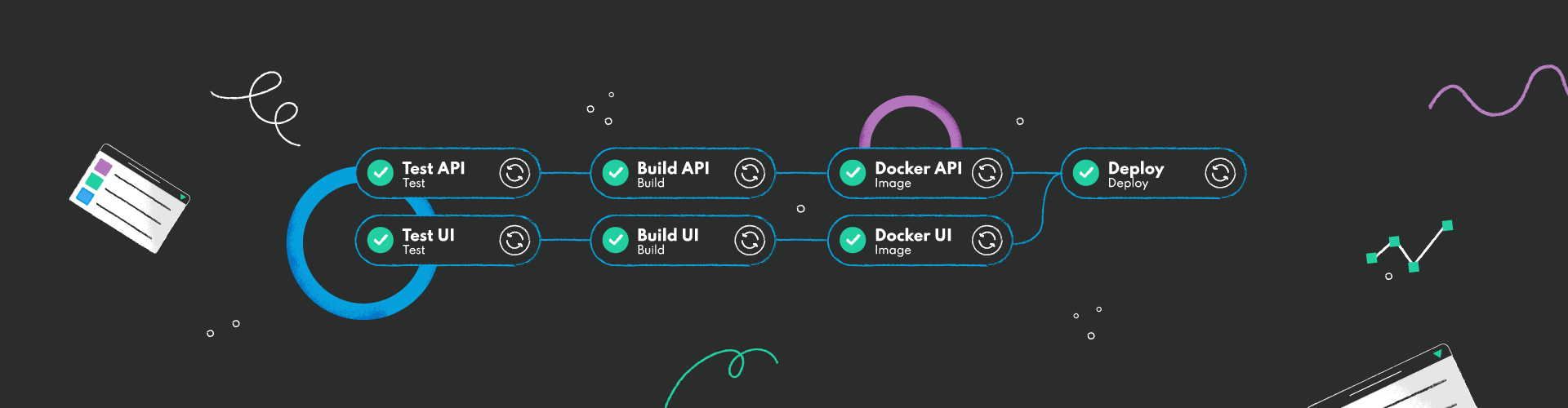
The pipeline consists of stages and jobs. As the name suggests, a job is a particular job to do, e.g., building your application. Jobs that can run at the same time are grouped into the same stage. Look at the example pipeline. There are four stages: Test stage, Build stage, Image stage, and Deploy stage. Each of them runs its own tasks, ex. Test contains jobs: Test API and Test UI.
Jobs in pipelines depend on each other. A pipeline job may require some input, produce some output, use a cache, and need some configuration.
Suppose you want to run pipelines on your own. In that case, you need a better understanding of artifacts and cache, which allows jobs to share data between jobs, as well as environment variables that will enable jobs to work according to provided configuration.
Artifacts
To deploy an application, you probably need docker images. To create docker images, you need to build your application. To build your application, you have to be sure that unit tests pass, etc.
If you preview the dependency graph for any GitLab project, you may notice that jobs depend on each other. Defining such dependencies is required because a single job doesn’t do the whole job on its own.
Dependencies between jobs
Job needs some input from a previous job and produces some output for consecutive jobs. - this data, which is passed between jobs, is called an artifact.
Using artifacts allows a job to prepare a small portion of data, archive it and pass it to another job. Thanks to that, jobs have low complexity because they are responsible only for a single thing.
For optimization purposes, you may use cache. The cache is excellent for downloading external dependencies like 3rd-party libraries.
If your list of dependencies has not changed, there is no need to download dependencies for each test run or build.
In contrast to artifacts, the cache is shared between pipelines. More on caching here:
https://docs.gitlab.com/ee/ci/caching/
CI/CD Variables
The repository is accessed by all team members, so not everything should be stored there, I mean secrets ex.: credentials, connections strings, etc.
To protect such sensitive data, in GitLab, you can define environment variables that may be accessed only by project maintainers. Variables may be accessed in the .gitlab-ci.yml file using the variable key, without exposing its value.
Additionally, you may also want to use information about your build environment, e.g., allow running deploy jobs only on the main branch, etc. To do so, you can use some
predefined variables.
Gitlab CI/CD variables are a great solution that allows you to customize your CI/CD pipelines and protect your secrets.
At first glance, GitLab pipelines may look like a black box, but it is a little less scary if you understand how it uses Artifacts, Cache, and CI/CD.
Probably you know how to compile, run tests or build your project on a local machine. You also know how to build and run docker images on your machine.
How is it possible that a web application like Gitlab executes such a tremendous job?
The response is Gitlab Runners & Gitlab Executors.
Gitlab Runner is an open-sourced service written in Go that is responsible for running your pipeline. It communicates with Gitlab and delegates jobs to executors.
Each runner, when it becomes available, sends requests to the GitLab instance, asking to be assigned jobs.
GitLab, when asked, is responsible for dividing work between runners. Still, most of the effort is done by runners and executors, which is good because it allows sharing the workload between multiple servers.
Interesting fact. In the beginning, runners were written in Ruby, which requires Ruby with its dependencies. It was heavy.
In 2015 Kamil Trzciński created his own runner written in Go as a side task, which is great for multi-tasking and parallelization. GitLab noticed this brilliant solution, and right now, it is a default runner used by Gitlab. You can learn more about it from Kamil’s presentation on
Youtube. Kamil works for GitLab now.
Are GitLab Runners Safe?
As a default, you may want to use shared runners provided by GitLab. You may be afraid that using runners installed on servers managed by GitLab may be risky because your source code may leak. This is a reasonable concern.
But, instead of using shared runners, you can use
your own runners installed on your machine. It is a better solution due to performance and security reasons.
You can register several runners and use them the whole time without usage limitations
defined by GitLab, which right now is 400 minutes in the free tier. It means that you can collaborate with your team members without any unwanted interruptions, which is necessary for continuous integration.
For beginners, I recommend using your own GitLab runner installed as a
docker container because it is great for fast prototyping.
What is also essential, Gitlab CI/CD runs on the machines of your choice. This means that the whole source code is downloaded to the machine managed by you. For sure, runners managed by GitLab are secure, but still - you never know.
What Are Gitlab Executors?
An executor is a service that receives assignments from the runner and executes jobs defined in .gitlab-ci.yml. Several types of executors allow you to select an environment where the job is executed. The simplest one is shell executor, which uses a shell on the machine where the runner is installed - it means that it may be your laptop. Unfortunately, shell executor does not guarantee a clean environment for each job and requires manual installation of the necessary software.
I recommend using the
docker executor for beginners, which guarantees a new environment for each pipeline run. Decision upon executor may be done when registering your runner in GitLab.
Gitlab Runner Execution Flow
Let’s see how runners and executors collaborate with Gitlab, looking at
GitLab runner execution flow. This is how an entire pipeline is executed.
Gitlab runner execution flow
First of all, GitLab must be aware that such an executor exists, and for security reasons, must be sure that it is a runner managed by the owner of the repository. To gain access to the repository, the runner must be registered using the token provided by GitLab. It is a pretty straightforward process. As I already mentioned, I recommend using
GitLab runner installed in a container.
Then the runner is asking for jobs to execute. If there is something to do, the runner downloads job details and triggers an executor. Executor clones the git repository, downloads artifacts, and executes jobs defined in .gitlab-ci.yml.
When an executor is done, it uploads job output and job status to GitLab.
GitLab Pipeline Jobs
To better understand GitLab runners, let’s see the example GitLab
repository, with pipelines and jobs defined in .gitlab-ci.yml. The pipeline consists of four jobs as follows: update artifact, update cache, update C&A, and check, which verifies the final status of the pipeline.
Example pipeline jobs
Each job executes the same commands, which display the content of the working directory and show the content of cache and artifact files.
- ls # show all files and directories in working directory
- if test -f ./cache-file; then cat ./cache-file; fi; # cat content of cache-file
- if test -f ./artifact-file; then cat ./artifact-file; fi; # cat content of artifact-file
For the sake of simplicity, I use only one file as cache and one file as an artifact, but you can also define a whole directory.
Additionally, jobs have their responsibilities:
Job update artifact adds some text to artifact-file
- echo "artifact updated in job 1A, secret [$SECRET_KEY], on branch [$CI_COMMIT_BRANCH]">>./artifact-file
Job update cache also adds some text, but to cache-file
- echo "cache created in job 1B, secret [$SECRET_KEY], on branch [$CI_COMMIT_BRANCH]">>./cache-file
Job update C&A updates both cache and artifact:
- echo "update artifact in job 2A, secret [$SECRET_KEY], on branch [$CI_COMMIT_BRANCH]">>./artifact-file
- echo "update cache in job 2A, secret [$SECRET_KEY], on branch [$CI_COMMIT_BRANCH]">>./cache-file
Note usage of predefined variable CI_COMMIT_BRANCH and environment variable SECRET_KEY defined in repository CI/CD settings below. Variables will be injected into docker containers when the pipeline runs.
GitLab Environment Variables
That’s basically it. As you can see, jobs are straightforward, the only responsibility of the job is to create or update files, but it is excellent for further explanation.
You can say that this is not a practical application for GitLab pipelines, but that’s what most of the pipelines do in real projects. Based on source code, build files are created - it may be a jar file, dist directory, or docker image, but still, it is only a set of files.
Gitlab Runner Step by Step
Gitlab runner may run multiple jobs defined in gitlab-ci.yml. Let’s see how the specific runner operates, looking at the
very first job executed in the pipeline. In job logs, you can find several exciting entries.
Download a docker image inside which the whole job is executed - in this case, it is a very lightweight Linux instance called
alpine.
Using Docker executor with image alpine ...
Pulling docker image alpine ...
Clone the git repository and mount it inside the docker container.
Getting source from Git repository
Created fresh repository.
Checking out 0e585cb3 as main…
Restore cache based on the key, which is calculated based on file cache-key in the repository. In real-life projects, cache keys could be calculated on build.gradle or package.json. As default, the cache is stored where GitLab Runner is installed - so there is no need to download cache from any external server.
Checking cache for 1069cd7938a4180b9c6b962f6476ed257d5c2a35...
Successfully extracted cache
Note that there is no need to download job artifacts because job artifacts are accessible within the same pipeline, on the machine where Gitlab Runner is installed and where each job is executed.
Execute shell script defined in yml file.
Execute job defined in gitlab-ci.yml
Executing "step_script" stage of the job script
Using docker image sha256:14119a... for alpine
After the job is done, preserve the updated cache for future use.
Saving cache for successful job
Creating cache a9406f87e1a5d81018be360ad0ca2f3f0b38fa37...
No URL provided, cache will be not uploaded to shared cache server. Cache will be stored only locally.
After the job is done, upload job artifacts to make them available on Gitlab
UI.
Uploading artifacts...
./artifact-file: found 1 matching files and directories
Uploading artifacts as "archive" to coordinator...
That’s basically it. If the exit code is zero, it means that the job succeeded.
Cleaning up project directory and file based variables
Job succeeded
Artifacts and Cache Operations
Let’s see how artifacts and cache files (that are not under source control) are used by
GitLab pipelines based on the example below.
There are three pipelines in this repository, which are started on the same main branch.
Executed GitLab pipelines
First Pipeline
First pipeline started with a fresh environment
The first pipeline is the first one that is started in the repository, with a brand new environment.
Let’s see the output of the very first run of the update artifacts job. The same situation is for the very first run of the update cache job.
$ ls
README.md
cache-key
$ if test -f ./cache-file; then cat ./cache-file; fi;
$ if test -f ./artifact-file; then cat ./artifact-file; fi;
$ echo "artifact updated in job 1A, secret [$SECRET_KEY], on branch [$CI_COMMIT_BRANCH]">>./artifact-file
As you can see, there are only two files in the working directory - these are files from the repository - *README.md *and cache-key. There is no cache-file nor artifact-file.
A different situation is for the consecutive job: update C&A.
$ ls
README.md
artifact-file
cache-file
cache-key
$ if test -f ./cache-file; then cat ./cache-file; fi;
cache created in job 1B, secret [secret_value], on branch [main]
$ if test -f ./artifact-file; then cat ./artifact-file; fi;
artifact updated in job 1A, secret [secret_value], on branch [main]
As you can see, there are two additional files:
artifact-file with content artifact updated in job 1A, secret [secret_value], on branch [main]
cache-file with content cache created in job 1B, secret [secret_value], on branch [main]
It means that both cache and artifact files are accessible for consecutive jobs in the pipeline.
Second Pipeline
A
second pipeline has access only to cache files. Look at the output for the first job in the second pipeline - update artifacts:
$ ls
README.md
cache-file
cache-key
$ if test -f ./cache-file; then cat ./cache-file; fi;
cache created in job 1B, secret [secret_value], on branch [main]
update cache in job 2A, secret [&SECRET_KEY], on branch [main]
$ if test -f ./artifact-file; then cat ./artifact-file; fi;
There is only a cache-file available. It means that cache is shared between pipelines, but artifacts don’t.
Third Pipeline
After the second pipeline finished, the file cache-keywas updated. It means that the cache was invalidated and couldn’t be used anymore.
Let’s see at the
third pipeline. After the cache-key update, job update artifacts didn’t have access to the outdated cache, as you can see below
$ ls
README.md
cache-key
$ if test -f ./cache-file; then cat ./cache-file; fi;
$ if test -f ./artifact-file; then cat ./artifact-file; fi;
There were only two files in the working directory, as at the beginning.
Gitlab CI/CD Is for Humans
Getting acquainted with GitLab runner execution flow allowed me to understand that running pipelines on GitLab is just running the same command that I could run on my local machine.
The main difference is that Gitlab pipelines allow collaboration and provide a clean environment for each build because docker images may be used. An environment that ensures repeatability is the essential requirement of the software development lifecycle with CI/CD configured.
Thanks to artifacts and cache, results of commands may be accessed for consecutive jobs and allow caching to prevent downloading the same data all the time.
If you understand the basic concepts of GitLab pipelines, feel free to clone
this repository and run some experiments on your new CI/CD project. You can run some jobs only on a specific branch; you can open merge requests and run jobs after merging. You could detect code changes and run some jobs if there were changes in particular directories.
Wojciech enjoys working with small teams where the quality of the code and the project's direction are essential. In the long run, this allows him to have a broad understanding of the subject, develop personally and look for challenges. He deals with programming in Java and Kotlin. Additionally, Wojciech is interested in Big Data tools, making him a perfect candidate for various Data-Intensive Application implementations.
What goes on behind the scenes in our engineering team? How do we solve large-scale technical challenges? How do we ensure our applications run smoothly? How do we perform testing and strive for clean code?
Follow our article series to get insight into our developers' current work and learn from their experience. Expect to see technical details, architecture discussions, reviews on libraries and tools we use, best practices on software quality, and maybe even some fail stories.
In the interests of your safety and to implement the principle of lawful, reliable and transparent
processing of your personal data when using our services, we developed this document called the
Privacy Policy. This document regulates the processing and protection of Users’ personal data in
connection with their use of the Website and has been prepared by Nexocode.
To ensure the protection of Users' personal data, Nexocode applies appropriate organizational and
technical solutions to prevent privacy breaches. Nexocode implements measures to ensure security at
the level which ensures compliance with applicable Polish and European laws such as:
Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on
the protection of natural persons with regard to the processing of personal data and on the free
movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation)
(published in the Official Journal of the European Union L 119, p 1);
Act of 10 May 2018 on personal data protection (published in the Journal of Laws of 2018, item
1000);
Act of 18 July 2002 on providing services by electronic means;
Telecommunications Law of 16 July 2004.
The Website is secured by the SSL protocol, which provides secure data transmission on the Internet.
1. Definitions
User – a person that uses the Website, i.e. a natural person with full legal capacity, a legal
person, or an organizational unit which is not a legal person to which specific provisions grant
legal capacity.
Nexocode – NEXOCODE sp. z o.o. with its registered office in Kraków, ul. Wadowicka 7, 30-347 Kraków, entered into the Register of Entrepreneurs of the National Court
Register kept by the District Court for Kraków-Śródmieście in Kraków, 11th Commercial Department
of the National Court Register, under the KRS number: 0000686992, NIP: 6762533324.
Website – website run by Nexocode, at the URL: nexocode.com whose content is available to
authorized persons.
Cookies – small files saved by the server on the User's computer, which the server can read when
when the website is accessed from the computer.
SSL protocol – a special standard for transmitting data on the Internet which unlike ordinary
methods of data transmission encrypts data transmission.
System log – the information that the User's computer transmits to the server which may contain
various data (e.g. the user’s IP number), allowing to determine the approximate location where
the connection came from.
IP address – individual number which is usually assigned to every computer connected to the
Internet. The IP number can be permanently associated with the computer (static) or assigned to
a given connection (dynamic).
GDPR – Regulation 2016/679 of the European Parliament and of the Council of 27 April 2016 on the
protection of individuals regarding the processing of personal data and onthe free transmission
of such data, repealing Directive 95/46 / EC (General Data Protection Regulation).
Personal data – information about an identified or identifiable natural person ("data subject").
An identifiable natural person is a person who can be directly or indirectly identified, in
particular on the basis of identifiers such as name, identification number, location data,
online identifiers or one or more specific factors determining the physical, physiological,
genetic, mental, economic, cultural or social identity of a natural person.
Processing – any operations performed on personal data, such as collecting, recording, storing,
developing, modifying, sharing, and deleting, especially when performed in IT systems.
2. Cookies
The Website is secured by the SSL protocol, which provides secure data transmission on the Internet.
The Website, in accordance with art. 173 of the Telecommunications Act of 16 July 2004 of the
Republic of Poland, uses Cookies, i.e. data, in particular text files, stored on the User's end
device. Cookies are used to:
improve user experience and facilitate navigation on the site;
help to identify returning Users who access the website using the device on which Cookies were
saved;
creating statistics which help to understand how the Users use websites, which allows to improve
their structure and content;
adjusting the content of the Website pages to specific User’s preferences and optimizing the
websites website experience to the each User's individual needs.
Cookies usually contain the name of the website from which they originate, their storage time on the
end device and a unique number. On our Website, we use the following types of Cookies:
"Session" – cookie files stored on the User's end device until the Uses logs out, leaves the
website or turns off the web browser;
"Persistent" – cookie files stored on the User's end device for the time specified in the Cookie
file parameters or until they are deleted by the User;
"Performance" – cookies used specifically for gathering data on how visitors use a website to
measure the performance of a website;
"Strictly necessary" – essential for browsing the website and using its features, such as
accessing secure areas of the site;
"Functional" – cookies enabling remembering the settings selected by the User and personalizing
the User interface;
"First-party" – cookies stored by the Website;
"Third-party" – cookies derived from a website other than the Website;
"Facebook cookies" – You should read Facebook cookies policy: www.facebook.com
"Other Google cookies" – Refer to Google cookie policy: google.com
3. How System Logs work on the Website
User's activity on the Website, including the User’s Personal Data, is recorded in System Logs. The
information collected in the Logs is processed primarily for purposes related to the provision of
services, i.e. for the purposes of:
analytics – to improve the quality of services provided by us as part of the Website and adapt
its functionalities to the needs of the Users. The legal basis for processing in this case is
the legitimate interest of Nexocode consisting in analyzing Users' activities and their
preferences;
fraud detection, identification and countering threats to stability and correct operation of the
Website.
4. Cookie mechanism on the Website
Our site uses basic cookies that facilitate the use of its resources. Cookies contain useful
information
and are stored on the User's computer – our server can read them when connecting to this computer
again.
Most web browsers allow cookies to be stored on the User's end device by default. Each User can
change
their Cookie settings in the web browser settings menu:
Google ChromeOpen the menu (click the three-dot icon in the upper right corner), Settings >
Advanced. In
the "Privacy and security" section, click the Content Settings button. In the "Cookies and site
date"
section you can change the following Cookie settings:
Deleting cookies,
Blocking cookies by default,
Default permission for cookies,
Saving Cookies and website data by default and clearing them when the browser is closed,
Specifying exceptions for Cookies for specific websites or domains
Internet Explorer 6.0 and 7.0
From the browser menu (upper right corner): Tools > Internet Options >
Privacy, click the Sites button. Use the slider to set the desired level, confirm the change with
the OK
button.
Mozilla Firefox
browser menu: Tools > Options > Privacy and security. Activate the “Custom” field.
From
there, you can check a relevant field to decide whether or not to accept cookies.
Opera
Open the browser’s settings menu: Go to the Advanced section > Site Settings > Cookies and site
data. From there, adjust the setting: Allow sites to save and read cookie data
Safari
In the Safari drop-down menu, select Preferences and click the Security icon.From there,
select
the desired security level in the "Accept cookies" area.
Disabling Cookies in your browser does not deprive you of access to the resources of the Website.
Web
browsers, by default, allow storing Cookies on the User's end device. Website Users can freely
adjust
cookie settings. The web browser allows you to delete cookies. It is also possible to automatically
block cookies. Detailed information on this subject is provided in the help or documentation of the
specific web browser used by the User. The User can decide not to receive Cookies by changing
browser
settings. However, disabling Cookies necessary for authentication, security or remembering User
preferences may impact user experience, or even make the Website unusable.
5. Additional information
External links may be placed on the Website enabling Users to directly reach other website. Also,
while
using the Website, cookies may also be placed on the User’s device from other entities, in
particular
from third parties such as Google, in order to enable the use the functionalities of the Website
integrated with these third parties. Each of such providers sets out the rules for the use of
cookies in
their privacy policy, so for security reasons we recommend that you read the privacy policy document
before using these pages.
We reserve the right to change this privacy policy at any time by publishing an updated version on
our
Website. After making the change, the privacy policy will be published on the page with a new date.
For
more information on the conditions of providing services, in particular the rules of using the
Website,
contracting, as well as the conditions of accessing content and using the Website, please refer to
the
the Website’s Terms and Conditions.
Nexocode Team
Want to be a part of our engineering team?
Join our teal organization and work on challenging projects.