Some time ago, I created a
repository that allowed for fast prototyping of web applications written in Spring and Vue.js. Read more
on the blog.
The application was a skeleton, ready to be deployed on AWS EC2. It could be accessed by IP address or your domain.
It was prepared to meet basic requirements of web applications: SPA UI, Spring Boot backend with access database, mailing service, and some network configuration allowing access to the application from the browser.
It included many tools: Spring Boot application, Vue.js, MongoDB, Docker, Traefik reverse proxy, AWS EC2 configuration, setup for a domain, Cloudflare, and Mailgun.
Unfortunately, if you would like to use it, the application had to be built and deployed from your computer. You would have to execute build scripts and call docker commands on your own. It is a serious drawback if you need to cooperate with other team members because there is no central point where integration occurs.
To allow collaboration, you need some CI/CD environment. That’s where GitLab comes into play. You can clone my new GitLab repository
seed-spring-vue-aws-ec2, make some basic configuration explained in README.md, and Gitlab CI/CD pipelines will deploy your web application.
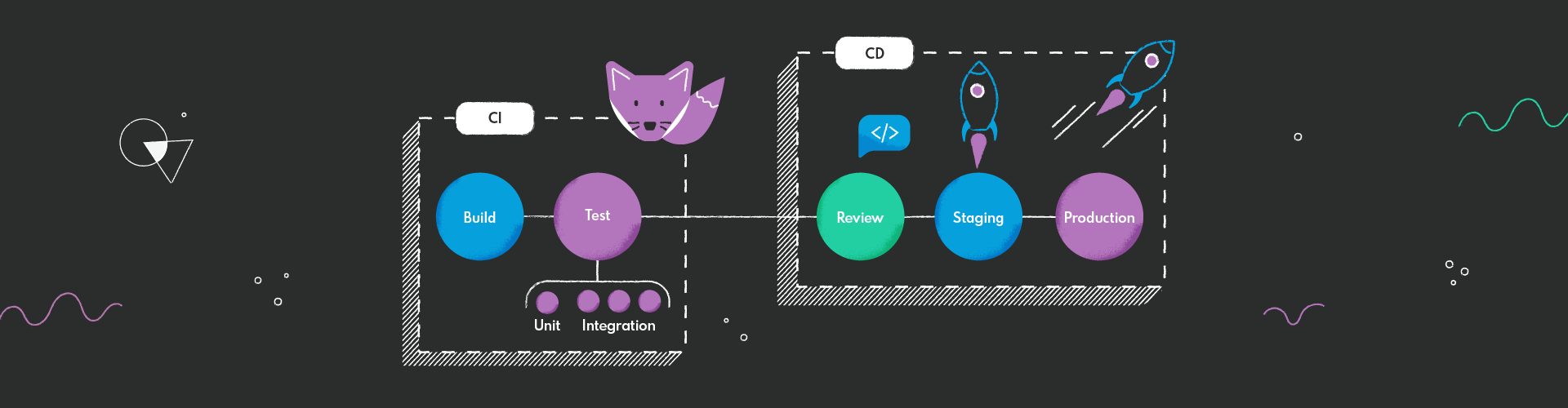
Pipeline lifecycle allowing to deploy a web application on AWS EC2
Let’s Use This Project and Deploy the Web App on EC2!
Before we explain how the GitLab CI/CD pipeline does the job for this repository, let’s start with something practical that will encourage further reading. Let’s deploy the web application on EC2 in 10 easy steps.
Run the application and make it accessible by your domain
[readme]
You’re all set – a coffee time before you start coding on your own is recommended at this stage.
To observe the effects of your efforts, visit your domain. You should be able to see the application ready for further development. You can also visit my domain to see how it works in real life –
https://wmarusarz.space.
Web application created in this project
The application, when opened, sends a request to verify communication between UI and API – you can see it in the browser Dev Tool in the Network tab. Additionally, if you have configured SMTP, you can also verify if emails are sent.
Networking Schema for the Application
The application operation schema is shown below, it is self-explanatory, but you can read more
here.
Networking schema for web application
Pipeline Stages and Jobs Explained
If you need a better understanding of GitLab pipelines, you can read my
previous article.
The pipeline defined for this project has to build UI and API, create Docker images for them, push images to the repository and run applications and other services like MongoDB and Traefik.
This pipeline contains several tasks grouped into four stages:
Build with tasks build:api responsible for running tests and building a jar file and build:ui responsible for building UI application
Setup with task setup-ec2 responsible for installing required packages and configuration of EC2 server
Image with tasks image:api and image:ui responsible for building docker images with
Spring Boot application and Vue.js application, and as well as for pushing images to ECR, which is a docker image repository from AWS
Deploy with tasks deploy:IP and deploy:domain that downloads docker images from ECR and runs them on EC2 instance as docker container alongside MongoDB and Traefik, which are also run as a Docker container.
GitLab AWS EC2 pipeline
It is a pretty simple pipeline, but valuable and for the sake of this application, it does the job.
Pipeline Explained
Stories on software engineering straight to your inbox
If you would like to use this project, you will probably need to update it according to your needs. To make it easier, you need to understand what’s going on here.
Maybe you would like to add some additional validations before applications are built. Perhaps you would like to pass some parameters for building commands, etc.
Maybe even one day, instead of a Spring Boot project, you would like to use Struts or Play. Perhaps instead of Vue.js, you would like like to use React.js or Angular. You never know.
So, how does this pipeline work?
I will show gitlab-ci.yml configuration for each job and will try to explain how each job leads to the deployment of the application
It is interruptible, which means a job can be canceled when made redundant by a newer run.
The result of this job is an artifact with a jar file. To build a jar file, there are specific requirements for a build environment. In this case, we want to use the docker image openjdk:11-jdk-slim, which is a Debian distribution with OpenJDK 11 pre-installed.
Before the script, we make some preparation. Replace version of Gradle used from x.x.x-all to x.x.x-bin. We don’t need a version with binaries, sources, and documentation for a build process - binaries are enough.
sed -i s/-all/-bin/ seed-spring/gradle/wrapper/gradle-wrapper.properties
The primary purpose of this task is to run a script that will run tests, checks and that will build a jar file for the Spring Boot app
./seed-spring/gradlew build
After the script, we need to do some cleanup that will allow running for the next job, which uses Gradle cache
This job creates artifacts in directory ./seed-spring/build/libs/. The most important is seed-spring-0.0.1-SNAPSHOT.jar, a jar file with an application and will be used inside the API Docker image.
Spring Boot application artifacts
This job also uses cache to speed up consecutive builds. The cache contains three directories
wrapper, to avoid downloading Gradle for each build
Gradle caches with 3-rd party libraries
Cache dependency-check-data, used by the plugin which verifies dependencies updates
It is interruptible, which means a job can be canceled when made redundant by a newer run.
The result of this job is an artifact with a dist directory. To build minified files, there are specific requirements for a build environment. In this case, we want to use docker image node:16 which is a Debian distribution with node.js and npm installed.
The main job is to run two commands
npm install to download required 3-rd party libraries defined in package.json
npm run build to build production-ready sources.
This job creates artifacts in the ./seed-vue/dist directory, which contains build results as follows:
Vue.js app artifacts
This job also uses cache to speed up consecutive builds. Cache files contain libraries defined in package.json, downloaded to node_modules directory.
The primary purpose of this job is to install the AWS command-line interface (aws-cli) and Docker on the EC2 server. The whole application will be served from there. An EC2 instance is an Ubuntu distribution. Instead of installing dependencies using shell commands, we run the Ansible script, which is excellent for configuring remote servers. It is a one-time operation, but you can execute it several times without side effects.
Before the Ansible script is triggered, Ansinbe needs to be aware of the IP address and have an SSH key provided to allow connection to a remote server. It is done in the before_script section.
This job is responsible for creating a docker image with a Spring Boot application that will run inside a docker container and push it to AWS ECR.
Docker image is built using kaniko. Why can’t we just use any image with Docker installed? As explained on the
Google Cloud blog:
Building images from a standard Dockerfile typically relies upon interactive access to a Docker daemon, which requires root access on your machine to run. This can make it difficult to build container images in environments that can’t easily or securely expose their Docker daemons
Kaniko can overcome these challenges for Gitlab pipelines.
Kaniko supports AWS ECR, but it needs information on authenticating to ECR to push docker images. Thanks to a configuration stored in config.json, kaniko knows that environment variables (configured in GitLab) have to be used. These variables are AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY.
This job is responsible for executing the Ansible script that downloads and starts all docker images. When docker images are up and running, the application is accessible by domain address of your own.
This job depends on image:api and image:ui, but it doesn’t need any artifacts because it uses docker images from ECR.
Before running the Ansible script, Ansible has to be aware of the server address where the script will be executed, and it needs an SSH key that allows connecting to the server. An SSH key is defined in GitLab repository environment variables as SSH_KEY_EC2
Still, this application is far from being ready for production. Still, it has some limitations, which you can find in
my previous article summary. Still, it has a considerable advantage compared to prior versions of the application - it allows collaboration and provides a clean environment for builds.
Thanks to that, you can work with your team, and anyone can make the deployment. Updating software on your laptop, laptop crash, or any other accident does not interfere with the further development of the application.
If you need a better understanding of GitLab pipelines, you can read my
previous article here.
Feel free to clone this GitLab repository
seed-spring-vue-aws-ec2 and make use of it for your own purposes. Probably you will have to adjust it to your needs, but right now, you know how to do it.
Wojciech enjoys working with small teams where the quality of the code and the project's direction are essential. In the long run, this allows him to have a broad understanding of the subject, develop personally and look for challenges. He deals with programming in Java and Kotlin. Additionally, Wojciech is interested in Big Data tools, making him a perfect candidate for various Data-Intensive Application implementations.
What goes on behind the scenes in our engineering team? How do we solve large-scale technical challenges? How do we ensure our applications run smoothly? How do we perform testing and strive for clean code?
Follow our article series to get insight into our developers' current work and learn from their experience. Expect to see technical details, architecture discussions, reviews on libraries and tools we use, best practices on software quality, and maybe even some fail stories.
In the interests of your safety and to implement the principle of lawful, reliable and transparent
processing of your personal data when using our services, we developed this document called the
Privacy Policy. This document regulates the processing and protection of Users’ personal data in
connection with their use of the Website and has been prepared by Nexocode.
To ensure the protection of Users' personal data, Nexocode applies appropriate organizational and
technical solutions to prevent privacy breaches. Nexocode implements measures to ensure security at
the level which ensures compliance with applicable Polish and European laws such as:
Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on
the protection of natural persons with regard to the processing of personal data and on the free
movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation)
(published in the Official Journal of the European Union L 119, p 1);
Act of 10 May 2018 on personal data protection (published in the Journal of Laws of 2018, item
1000);
Act of 18 July 2002 on providing services by electronic means;
Telecommunications Law of 16 July 2004.
The Website is secured by the SSL protocol, which provides secure data transmission on the Internet.
1. Definitions
User – a person that uses the Website, i.e. a natural person with full legal capacity, a legal
person, or an organizational unit which is not a legal person to which specific provisions grant
legal capacity.
Nexocode – NEXOCODE sp. z o.o. with its registered office in Kraków, ul. Wadowicka 7, 30-347 Kraków, entered into the Register of Entrepreneurs of the National Court
Register kept by the District Court for Kraków-Śródmieście in Kraków, 11th Commercial Department
of the National Court Register, under the KRS number: 0000686992, NIP: 6762533324.
Website – website run by Nexocode, at the URL: nexocode.com whose content is available to
authorized persons.
Cookies – small files saved by the server on the User's computer, which the server can read when
when the website is accessed from the computer.
SSL protocol – a special standard for transmitting data on the Internet which unlike ordinary
methods of data transmission encrypts data transmission.
System log – the information that the User's computer transmits to the server which may contain
various data (e.g. the user’s IP number), allowing to determine the approximate location where
the connection came from.
IP address – individual number which is usually assigned to every computer connected to the
Internet. The IP number can be permanently associated with the computer (static) or assigned to
a given connection (dynamic).
GDPR – Regulation 2016/679 of the European Parliament and of the Council of 27 April 2016 on the
protection of individuals regarding the processing of personal data and onthe free transmission
of such data, repealing Directive 95/46 / EC (General Data Protection Regulation).
Personal data – information about an identified or identifiable natural person ("data subject").
An identifiable natural person is a person who can be directly or indirectly identified, in
particular on the basis of identifiers such as name, identification number, location data,
online identifiers or one or more specific factors determining the physical, physiological,
genetic, mental, economic, cultural or social identity of a natural person.
Processing – any operations performed on personal data, such as collecting, recording, storing,
developing, modifying, sharing, and deleting, especially when performed in IT systems.
2. Cookies
The Website is secured by the SSL protocol, which provides secure data transmission on the Internet.
The Website, in accordance with art. 173 of the Telecommunications Act of 16 July 2004 of the
Republic of Poland, uses Cookies, i.e. data, in particular text files, stored on the User's end
device. Cookies are used to:
improve user experience and facilitate navigation on the site;
help to identify returning Users who access the website using the device on which Cookies were
saved;
creating statistics which help to understand how the Users use websites, which allows to improve
their structure and content;
adjusting the content of the Website pages to specific User’s preferences and optimizing the
websites website experience to the each User's individual needs.
Cookies usually contain the name of the website from which they originate, their storage time on the
end device and a unique number. On our Website, we use the following types of Cookies:
"Session" – cookie files stored on the User's end device until the Uses logs out, leaves the
website or turns off the web browser;
"Persistent" – cookie files stored on the User's end device for the time specified in the Cookie
file parameters or until they are deleted by the User;
"Performance" – cookies used specifically for gathering data on how visitors use a website to
measure the performance of a website;
"Strictly necessary" – essential for browsing the website and using its features, such as
accessing secure areas of the site;
"Functional" – cookies enabling remembering the settings selected by the User and personalizing
the User interface;
"First-party" – cookies stored by the Website;
"Third-party" – cookies derived from a website other than the Website;
"Facebook cookies" – You should read Facebook cookies policy: www.facebook.com
"Other Google cookies" – Refer to Google cookie policy: google.com
3. How System Logs work on the Website
User's activity on the Website, including the User’s Personal Data, is recorded in System Logs. The
information collected in the Logs is processed primarily for purposes related to the provision of
services, i.e. for the purposes of:
analytics – to improve the quality of services provided by us as part of the Website and adapt
its functionalities to the needs of the Users. The legal basis for processing in this case is
the legitimate interest of Nexocode consisting in analyzing Users' activities and their
preferences;
fraud detection, identification and countering threats to stability and correct operation of the
Website.
4. Cookie mechanism on the Website
Our site uses basic cookies that facilitate the use of its resources. Cookies contain useful
information
and are stored on the User's computer – our server can read them when connecting to this computer
again.
Most web browsers allow cookies to be stored on the User's end device by default. Each User can
change
their Cookie settings in the web browser settings menu:
Google ChromeOpen the menu (click the three-dot icon in the upper right corner), Settings >
Advanced. In
the "Privacy and security" section, click the Content Settings button. In the "Cookies and site
date"
section you can change the following Cookie settings:
Deleting cookies,
Blocking cookies by default,
Default permission for cookies,
Saving Cookies and website data by default and clearing them when the browser is closed,
Specifying exceptions for Cookies for specific websites or domains
Internet Explorer 6.0 and 7.0
From the browser menu (upper right corner): Tools > Internet Options >
Privacy, click the Sites button. Use the slider to set the desired level, confirm the change with
the OK
button.
Mozilla Firefox
browser menu: Tools > Options > Privacy and security. Activate the “Custom” field.
From
there, you can check a relevant field to decide whether or not to accept cookies.
Opera
Open the browser’s settings menu: Go to the Advanced section > Site Settings > Cookies and site
data. From there, adjust the setting: Allow sites to save and read cookie data
Safari
In the Safari drop-down menu, select Preferences and click the Security icon.From there,
select
the desired security level in the "Accept cookies" area.
Disabling Cookies in your browser does not deprive you of access to the resources of the Website.
Web
browsers, by default, allow storing Cookies on the User's end device. Website Users can freely
adjust
cookie settings. The web browser allows you to delete cookies. It is also possible to automatically
block cookies. Detailed information on this subject is provided in the help or documentation of the
specific web browser used by the User. The User can decide not to receive Cookies by changing
browser
settings. However, disabling Cookies necessary for authentication, security or remembering User
preferences may impact user experience, or even make the Website unusable.
5. Additional information
External links may be placed on the Website enabling Users to directly reach other website. Also,
while
using the Website, cookies may also be placed on the User’s device from other entities, in
particular
from third parties such as Google, in order to enable the use the functionalities of the Website
integrated with these third parties. Each of such providers sets out the rules for the use of
cookies in
their privacy policy, so for security reasons we recommend that you read the privacy policy document
before using these pages.
We reserve the right to change this privacy policy at any time by publishing an updated version on
our
Website. After making the change, the privacy policy will be published on the page with a new date.
For
more information on the conditions of providing services, in particular the rules of using the
Website,
contracting, as well as the conditions of accessing content and using the Website, please refer to
the
the Website’s Terms and Conditions.
Nexocode Team
Want to be a part of our engineering team?
Join our teal organization and work on challenging projects.