In the world of data science, the process of collecting, cleaning, analyzing, and visualizing data can be complex and time-consuming. One way to streamline this process and improve efficiency is using data science pipelines. A data science pipeline is a series of automated steps that enable data scientists to quickly and consistently move data through the various stages of the data analysis workflow. By using data pipelines, data scientists can automate repetitive tasks, reduce the risk of errors, and accelerate the time to insights. It is also a crucial step for model deployment and results reproducibility.
In this article, we will explore the benefits of data science pipelines and how they can be implemented to improve your data analysis workflow.
The Importance of Streamlining the Data Analysis Workflow
The importance of streamlining the data analysis workflow cannot be overstated. In the world of data science, the process of collecting, cleaning, exploratory data analysis, and data visualization can be complex and time-consuming. By streamlining this process, data scientists can reduce the risk of errors, accelerate the time to insights, and improve their work efficiency.
One way to streamline the data analysis workflow is by using data science pipelines, which are automated series of steps that enable data scientists to quickly and consistently move data through the various stages of the process. Using pipelines, data scientists can automate repetitive tasks, reduce the risk of errors, and accelerate the time to insights.
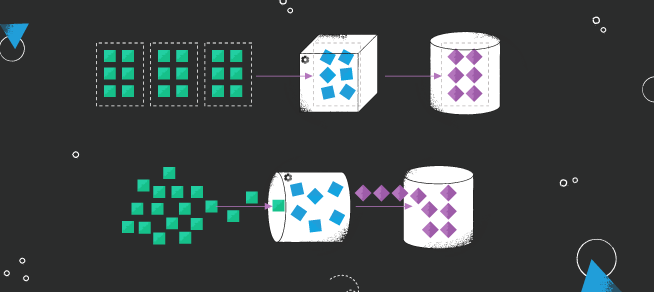
Data analytics pipeline - key steps
The Data Science Pipeline Process
Before starting a data science pipeline, it is crucial to clearly understand the problem you are trying to solve and the available data. This will help you to design an effective pipeline that meets the needs of your project and ensures that you are using the correct data for your analysis.
Having a clear problem statement and understanding of your data can also help you identify your analysis’s potential
challenges and limitations. For example, if you are working with incomplete or noisy data, you may need to adjust your pipeline accordingly to account for these issues.
Data science pipeline refers to a repeatable processes of continuous experimantation on the machine learning model development
Data science pipelines should be designed to streamline the data analysis process, improve efficiency, and ensure the reliability and transparency of the analysis. They usually consist of key stages:
Data Collection
The first step of the data science pipeline process is moving raw data - data collection. In this step, data is collected from various sources, such as databases, sensors, or user-generated content. The data sets may be structured (e.g., in a spreadsheet) or consist of unstructured, raw data (e.g., text data from social media or unlabelled image files).
Data Cleaning and Preprocessing
After data is collected, it is typically cleaned and preprocessed to remove errors and inconsistencies and to prepare it for analysis. This step is also known as data wrangling or data munging. Data cleaning may involve parsing, filtering, verifying missing values, and formatting the data to a more usable format.
Harness the full potential of AI for your business
After the data is cleaned, data scientists may begin to explore sample data to understand its characteristics and conduct data interpretation to identify patterns or trends. This step is also known as exploratory data analysis or data reviewing. Data exploration may involve visualizing the data, calculating summary statistics, or identifying correlations between variables.
Modeling Data and Interpreting Results
After exploring the data, data scientists may use statistical data models or machine learning algorithms to analyze the data and extract insights. This step is also known as data modeling. Data science teams may use various tools and techniques to conduct data transformation, build initial machine learning models and interpret the results, such as regression analysis, clustering, or classification.
Make Revisions
After analyzing the data and interpreting the results, data scientists may need to revise their analysis based on their findings. This may involve adjusting the model, changing the data, or identifying new research questions. The goal of this step is to ensure that the analysis is accurate and that the results are meaningful and bring actionable insights.
Machine learning lifecycle step-by-step
Key Features of Data Science Pipelines
Several key features are typically found in a modern data science pipeline:
Automation: Data science pipelines automate and streamline the collection, cleaning, analyzing, and visualizing data. By automating repetitive tasks, data science pipelines can reduce the risk of errors and improve the efficiency of the data analysis process.
Scalability: The key to a good data science pipeline is scalability, meaning it can handle large amounts of data, complex datasets, and multiple workloads. This is important as datasets and analysis requirements often grow over time, and modern businesses need to process more data as they evolve. They should also enable distributed processing for fast and scalable infrastructure.
Flexibility: Data science pipelines should be flexible enough to adapt to changing business requirements and data sources. This may involve looking for features such as modularity or configurability.
Reproducibility: Data science pipelines are designed to be reproducible, meaning they can be run multiple times with consistent results. This is important for ensuring the reliability and transparency of the analysis.
Documentation: Each data science pipeline should be well-documented, clearly explaining the steps taken and the results obtained. This is crucial for ensuring that the analysis is transparent and easy to understand.
Collaboration: Data science pipelines should be designed with collaboration in mind, allowing multiple data scientists to work on the same project and share results. This may involve using version control systems or collaboration tools.
Implementing Data Science Pipelines
Tools and Technologies Used to Implement Data Science Pipelines
There are a variety of tools and technologies that a data scientist should have in his toolkit. Some of the most common tools and technologies include:
Programming Languages
Data science pipelines are typically implemented using programming languages such as Python, R, Julia, or Scala. These languages provide a wide range of libraries and tools for data manipulation, analysis, and visualization.
IDE for Data Science Projects
There are several common IDEs (integrated development environments) that are frequently used for data science projects:
Jupyter: Jupyter is an open-source IDE widely used for data analysis and scientific computing. It enables users to create and share interactive documents that contain live code, equations, visualizations, and narrative text.
RStudio: RStudio is an IDE specifically designed for the R programming language. It provides various tools and features for data manipulation, visualization, and machine learning.
PyCharm: PyCharm is an IDE specifically designed for the Python programming language. It provides a range of code editing, debugging, and testing features, as well as support for data science and scientific computing.
Data Integration and Transformation Tools
Tools such as
Apache Spark, Pandas, or Dask can be used to efficiently extract, transform, and load data from various sources.
Data Storage Solutions
Data pipelines are a crucial part of any production data project, and often involve storing and processing large amounts of data. Tools such as Hadoop, Amazon S3, or Google Cloud Storage can manage and store data in a scalable and reliable manner and be part of a data warehouse or data lake architecture that enables batch processing of data.
Many modern data science projects rely on real-time data and therefore need access and integration with data streams to enable continuous data collection and analysis. This can be achieved through tools and technologies such as streaming data platforms, message brokers, or APIs (
Apache Kafka,
Apache Flink, etc.). By using real-time data streams to create a continuous data pipeline, businesses can build solutions that need to monitor and analyze data in near real-time continuously, providing critical business insights and enabling more timely decision-making (e.g., in financial institutions’ machine learning model for risk analysis, fraud detection, or in transportation industry solutions for predictive maintenance or accurate ETA predictions).
A data science pipeline will probably involve machine learning algorithms to analyze data. Libraries such as scikit-learn, TensorFlow, PyTorch, or Keras provide a range of algorithms and tools for building machine learning models (including deep learning algorithms support). Additionally, stream processing frameworks usually offer base machine learning algorithms (e.g., FlinkML in Apache Flink or MLlib in Apache Spark).
Each data science pipeline involves visualizing data to communicate insights. Data visualization is a vital part of various data science tools (e.g., Jupyter). Dedicated tools such as Matlab, Plotly, or Tableau can create a wide range of graphs and charts.
Not only data needs visualization.
Machine learning models need visualization tools as well to enable ease of tracking key model performance metrics such as evaluation metrics, performance charts, learning curves, or explainability metrics. If you’re looking for model visualization tools, verify solutions like TensorBoard, Weights & Biases, Neptune, or Comet.
Workflow Management and Scheduling Tools
Orchestration tools are software applications that enable users to automate and manage the various tasks and processes involved in data science pipelines. They provide a way to coordinate and schedule the various steps of the pipeline, ensuring that the tasks are executed in the correct order and at the appropriate times. Tools such as Apache Airflow, AWS Glue, or Azure Data Factory can automate and manage the various steps of the data science pipeline process.
If you’re looking for dedicated ML workflow orchestration tools you can also check the following solutions: Kale, Flyte, MLRun, Prefect, ZenML, or Kedro.
Best Practices for Designing and Building Data Science Pipelines
Several best practices can be followed when designing and building a data science pipeline:
Define Clear Goals and Objectives for Data Findings
Before building a data science pipeline, it is important to define clear goals and objectives for the analysis. This will help to ensure that the pipeline is focused on the most important tasks and that the results are meaningful and useful.
Identify and Prepare Raw Data
Data preparation is a crucial step in the data science pipeline process. It is important to identify the data sources relevant to the analysis and ensure that structured and unstructured data is cleaned and preprocessed appropriately.
Use Modular Design
Data science pipelines should be designed modularly, with each step of the process handled by a separate module. This will make it easier to test and debug the pipeline, and it will also make it easier to update or modify the pipeline as needed.
MLOps implementation - The process of model data preparation and model development with experiment tracking
Use Version Control
Data science pipeline works best with version control. This will allow multiple data scientists to collaborate on the same project and will also enable you to track and revert changes to the pipeline as needed (also data versioning and model versioning).
Implementing continuous integration for machine learning projects and a setup for version control and deployment to dev, stage, and prod environments
Test and Debug
Data science pipelines should be thoroughly tested and debugged to ensure they are working correctly. This may involve testing the pipeline on a small subset of the data and using tools such as log files or error tracking to identify and fix issues.
Step-by-step development operations executed at development, staging, and production environments
Monitor and Optimize
A data science pipeline should be regularly monitored and optimized to ensure that they are running efficiently and effectively. This may involve adjusting the pipeline to handle changes in the data or improving the performance of the pipeline by optimizing code or using more powerful hardware.
Common Challenges and Pitfalls to Avoid When Implementing Pipelines
Implementing data science pipelines can be a complex and challenging task, and there are a number of common challenges and pitfalls that data scientists need to be aware of:
Data quality and integrity: Ensuring the quality and integrity of the data assets used in a data science pipeline can be a major challenge. Data may be incomplete, inconsistent, or corrupted, and it is important to identify errors and address these issues to ensure that the results of the analysis are accurate and reliable.
Scalability and performance: As data sets and analysis requirements continue to grow, data science pipelines may need to scale to handle large amounts of data and processing power.
Integration with other systems: Data science pipelines may need to integrate with other systems or technologies, such as data warehouses, APIs, or data streams. Ensuring that the data pipeline can seamlessly integrate with these systems can be a major challenge, especially when working with real time streaming data.
Security and privacy: Protecting the security and privacy of data is essential when building data science pipelines. This may involve using secure protocols, encryption, and other measures to ensure that data is protected from unauthorized access or breaches.
The Benefits of Using a Data Science Pipeline
There are many benefits to using a data science pipeline for collecting, cleaning, analyzing, and visualizing data. Some of the key benefits include:
Improved efficiency,
Faster time to insights,
Enhanced collaboration,
Improved accuracy of results and model insights,
Reduced risk of errors.
Enhanced security and privacy of enterprise data,
Ability to handle large amounts of data,
Improved tracking and monitoring of data analysis processes,
Greater flexibility and adaptability to shifting business needs and requirements.
In conclusion, data science pipelines are essential for streamlining the process of collecting, cleaning, analyzing, and visualizing data. As data science continues to be a rapidly growing field, the future outlook for data science pipelines is very positive, with increasing demand for
data-driven insights and a wide range of tools and technologies available to support data analysis.
Krzysztof is a data scientist who applies machine learning and mathematical methods to solve business problems. He is particularly interested in developing end-to-end solutions for companies in various industries using deep learning and NLP techniques.
Mathematician, software developer, and trainer. Krzysztof's expertise in machine learning earned him a Google Developer Expert title. A fan of Albert's Einstein quote: "If you can't explain it simply, you don't understand it well enough."
Would you like to discuss AI opportunities in your business?
Let us know and Dorota will arrange a call with our experts.
Artificial Intelligence solutions are becoming the next competitive edge for many companies within various industries. How do you know if your company should invest time into emerging tech? How to discover and benefit from AI opportunities? How to run AI projects?
Follow our article series to learn how to get on a path towards AI adoption. Join us as we explore the benefits and challenges that come with AI implementation and guide business leaders in creating AI-based companies.
In the interests of your safety and to implement the principle of lawful, reliable and transparent
processing of your personal data when using our services, we developed this document called the
Privacy Policy. This document regulates the processing and protection of Users’ personal data in
connection with their use of the Website and has been prepared by Nexocode.
To ensure the protection of Users' personal data, Nexocode applies appropriate organizational and
technical solutions to prevent privacy breaches. Nexocode implements measures to ensure security at
the level which ensures compliance with applicable Polish and European laws such as:
Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on
the protection of natural persons with regard to the processing of personal data and on the free
movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation)
(published in the Official Journal of the European Union L 119, p 1);
Act of 10 May 2018 on personal data protection (published in the Journal of Laws of 2018, item
1000);
Act of 18 July 2002 on providing services by electronic means;
Telecommunications Law of 16 July 2004.
The Website is secured by the SSL protocol, which provides secure data transmission on the Internet.
1. Definitions
User – a person that uses the Website, i.e. a natural person with full legal capacity, a legal
person, or an organizational unit which is not a legal person to which specific provisions grant
legal capacity.
Nexocode – NEXOCODE sp. z o.o. with its registered office in Kraków, ul. Wadowicka 7, 30-347 Kraków, entered into the Register of Entrepreneurs of the National Court
Register kept by the District Court for Kraków-Śródmieście in Kraków, 11th Commercial Department
of the National Court Register, under the KRS number: 0000686992, NIP: 6762533324.
Website – website run by Nexocode, at the URL: nexocode.com whose content is available to
authorized persons.
Cookies – small files saved by the server on the User's computer, which the server can read when
when the website is accessed from the computer.
SSL protocol – a special standard for transmitting data on the Internet which unlike ordinary
methods of data transmission encrypts data transmission.
System log – the information that the User's computer transmits to the server which may contain
various data (e.g. the user’s IP number), allowing to determine the approximate location where
the connection came from.
IP address – individual number which is usually assigned to every computer connected to the
Internet. The IP number can be permanently associated with the computer (static) or assigned to
a given connection (dynamic).
GDPR – Regulation 2016/679 of the European Parliament and of the Council of 27 April 2016 on the
protection of individuals regarding the processing of personal data and onthe free transmission
of such data, repealing Directive 95/46 / EC (General Data Protection Regulation).
Personal data – information about an identified or identifiable natural person ("data subject").
An identifiable natural person is a person who can be directly or indirectly identified, in
particular on the basis of identifiers such as name, identification number, location data,
online identifiers or one or more specific factors determining the physical, physiological,
genetic, mental, economic, cultural or social identity of a natural person.
Processing – any operations performed on personal data, such as collecting, recording, storing,
developing, modifying, sharing, and deleting, especially when performed in IT systems.
2. Cookies
The Website is secured by the SSL protocol, which provides secure data transmission on the Internet.
The Website, in accordance with art. 173 of the Telecommunications Act of 16 July 2004 of the
Republic of Poland, uses Cookies, i.e. data, in particular text files, stored on the User's end
device. Cookies are used to:
improve user experience and facilitate navigation on the site;
help to identify returning Users who access the website using the device on which Cookies were
saved;
creating statistics which help to understand how the Users use websites, which allows to improve
their structure and content;
adjusting the content of the Website pages to specific User’s preferences and optimizing the
websites website experience to the each User's individual needs.
Cookies usually contain the name of the website from which they originate, their storage time on the
end device and a unique number. On our Website, we use the following types of Cookies:
"Session" – cookie files stored on the User's end device until the Uses logs out, leaves the
website or turns off the web browser;
"Persistent" – cookie files stored on the User's end device for the time specified in the Cookie
file parameters or until they are deleted by the User;
"Performance" – cookies used specifically for gathering data on how visitors use a website to
measure the performance of a website;
"Strictly necessary" – essential for browsing the website and using its features, such as
accessing secure areas of the site;
"Functional" – cookies enabling remembering the settings selected by the User and personalizing
the User interface;
"First-party" – cookies stored by the Website;
"Third-party" – cookies derived from a website other than the Website;
"Facebook cookies" – You should read Facebook cookies policy: www.facebook.com
"Other Google cookies" – Refer to Google cookie policy: google.com
3. How System Logs work on the Website
User's activity on the Website, including the User’s Personal Data, is recorded in System Logs. The
information collected in the Logs is processed primarily for purposes related to the provision of
services, i.e. for the purposes of:
analytics – to improve the quality of services provided by us as part of the Website and adapt
its functionalities to the needs of the Users. The legal basis for processing in this case is
the legitimate interest of Nexocode consisting in analyzing Users' activities and their
preferences;
fraud detection, identification and countering threats to stability and correct operation of the
Website.
4. Cookie mechanism on the Website
Our site uses basic cookies that facilitate the use of its resources. Cookies contain useful
information
and are stored on the User's computer – our server can read them when connecting to this computer
again.
Most web browsers allow cookies to be stored on the User's end device by default. Each User can
change
their Cookie settings in the web browser settings menu:
Google ChromeOpen the menu (click the three-dot icon in the upper right corner), Settings >
Advanced. In
the "Privacy and security" section, click the Content Settings button. In the "Cookies and site
date"
section you can change the following Cookie settings:
Deleting cookies,
Blocking cookies by default,
Default permission for cookies,
Saving Cookies and website data by default and clearing them when the browser is closed,
Specifying exceptions for Cookies for specific websites or domains
Internet Explorer 6.0 and 7.0
From the browser menu (upper right corner): Tools > Internet Options >
Privacy, click the Sites button. Use the slider to set the desired level, confirm the change with
the OK
button.
Mozilla Firefox
browser menu: Tools > Options > Privacy and security. Activate the “Custom” field.
From
there, you can check a relevant field to decide whether or not to accept cookies.
Opera
Open the browser’s settings menu: Go to the Advanced section > Site Settings > Cookies and site
data. From there, adjust the setting: Allow sites to save and read cookie data
Safari
In the Safari drop-down menu, select Preferences and click the Security icon.From there,
select
the desired security level in the "Accept cookies" area.
Disabling Cookies in your browser does not deprive you of access to the resources of the Website.
Web
browsers, by default, allow storing Cookies on the User's end device. Website Users can freely
adjust
cookie settings. The web browser allows you to delete cookies. It is also possible to automatically
block cookies. Detailed information on this subject is provided in the help or documentation of the
specific web browser used by the User. The User can decide not to receive Cookies by changing
browser
settings. However, disabling Cookies necessary for authentication, security or remembering User
preferences may impact user experience, or even make the Website unusable.
5. Additional information
External links may be placed on the Website enabling Users to directly reach other website. Also,
while
using the Website, cookies may also be placed on the User’s device from other entities, in
particular
from third parties such as Google, in order to enable the use the functionalities of the Website
integrated with these third parties. Each of such providers sets out the rules for the use of
cookies in
their privacy policy, so for security reasons we recommend that you read the privacy policy document
before using these pages.
We reserve the right to change this privacy policy at any time by publishing an updated version on
our
Website. After making the change, the privacy policy will be published on the page with a new date.
For
more information on the conditions of providing services, in particular the rules of using the
Website,
contracting, as well as the conditions of accessing content and using the Website, please refer to
the
the Website’s Terms and Conditions.
Nexocode Team
Want to unlock the full potential of Artificial Intelligence technology?
Download our ebook and learn how to drive AI adoption in your business.